» Improving on “Access to Research”
abernard102@gmail.com 2014-02-08
Access to Research is an initiative from a 20th Century industry attempting to stave off progress towards the 21st Century by applying a 19th Century infrastructure. Depending on how generous you are feeling it can either be described as a misguided waste of effort or as a cynical attempt to divert the community from tackling the real issues of implementing full Open Access. As is obvious I’m not a neutral observer here so I recommend reading the description at the website. Indeed I would also recommend anyone who is interested from taking a look at the service itself.
Building a map of sites
I was interested in possibly doing this myself. In many ways as a sometime researcher who no longer has access to a research library I’m exactly the target audience. Unfortunately the Access to Research website isn’t really very helpful. The Bath public library where I live isn’t a site, nor is Bristol. So which site is closest? Aylesbury perhaps? Or perhaps somewhere near to the places I visit in London. Unfortunately there is no map provided to help find your closest site. For an initiative that is supposed to be focused on user needs this might have been a fairly obvious thing to provide. But no problem, it is easy enough to create one myself, so here it is (click through for a link to the live map).
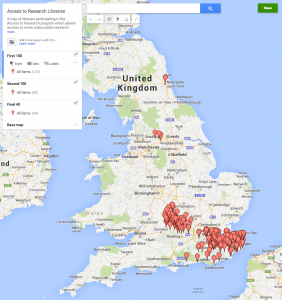
Access to Research for the UK…or at least certain corners of England anyway.
What I have done is to write some Python code that screen scrapes the Access to Research website to obtain the list of participating libraries, and their URLs. Then my little robot visits each of those library websites and looks for something that matches a UK post code. I’ve then uploaded that to Google Maps to create the map itself. You can also see a version of the code via the IPython Notebook Viewer. Of course the data and code is also available. All of this could easily be improved upon. Kent County Council don’t actually provide postcodes or even addresses for their libraries on their web pages. I’m sure someone could either fix the data or improve the code to create better data. It would also be nice to use an open source map visualisation rather than Google Maps to enable further re-use but I didn’t want to spend too long on this.
The irony
You might well ask why I would spend a Saturday afternoon making it easier to use an initiative which I feel is a cynical political ploy. The answer is to prove a point. The knowledge and skills I used to create this map are not rare – nor is the desire to contribute to making resources better and more useful for others. But in gathering this data and generating the map I’ve violated pretty much every restriction which traditional publishers want to apply to anyone using “their” work.
What I have done here is Text Mining. Something these publishers claim to support, but only under their conditions and licenses. Conditions that make it effectively impossible to do anything useful However I’ve done this without permission, without registration, and without getting a specific license to do so. All of this would be impossible if this were research that I had accessed through the scheme or if I had agreed to the conditions that publishers would like to lay down for us to carry out Content Mining.
Lets take a look at the restrictions you agree to to use the Access to Research service.
I can only use accessed information for non-commercial research and private study.
Well I work for a non-profit, but this is the weekend. Is that private? Not sure, but there are no ads on this website at least. On the other hand I’ve used a Google service. Does that make it commercial? Google are arguably benefiting from me adding data to their services, and the free service I used is a taster of the more powerful version they charge for.
I will only gain access through the password protected secure service
…oh well, not really, although I guess you might argue that there wasn’t an access restricted system in this case. But is access via a robot bypassing the ‘approved’ route?
I will not build any repository or other archive
…well there would hardly be any point if I hadn’t.
I will not download
…well that was the polite thing to do, grab a copy and process it to create the dataset. Otherwise I’d have to keep hitting the website over and over again. And that would be rude.
I will not forward, distribute, sell
…well I’m not selling it at least…
I will not adapt, modify
…ooops.
I will not make more than one copy…and I will not remove any copyright notices
…well there’s one copy on my machine, one on github, one in however many forks of the repo there are, one on Google…oh and there weren’t any copyright notices on the website. This probably makes it All Rights Reserved with an implied license to view and process the web page but the publisher argument that says I need a license for text mining would mean that I’m in violation of the implied license I would guess. I would argue that as I have only made as many copies required to process and that I have extracted facts to which copyright doesn’t apply I’m fine…but I’m not a lawyer, and this is not legal advice.
I will not modify…any digital rights information.
Well there’s one that I didn’t violate! Thank heavens for that. But only because there wasn’t any statement of usage conditions for the site data.
I will not allow the making of any derivative works
…oh dear…
I will not copy otherwise retain [sic] any [copies] onto my personal systems
…sigh
I agree not to rely on the publications as a substitute for specific medical, professional or expert advice.
What is ‘expert advice’ I wonder? In any case, don’t rely on the map if you’re in a mad rush.
I could easily go on with the conditions required to sign up for the Elsevier Text Mining program. Again I would either be in clear violation of most of them or it would be difficult to tell. Peter Murray-Rust has a more research-oriented dissection of the problems with the Elsevier conditions in several posts at his blog. Its also quite difficult to tell because Elsevier don’t make those conditions publicly available. The only version I have seen is on Peter’s Blog.
Conclusions
You may feel that I’m making an unfair comparison, that the research content that publishers want to control the use of is different and that the analysis I have done, and the value I have added is different to that involved in using, reading and analysing research. That is both incorrect, and missing the point. The web has brought us a rich set of tools and made it easy for those skilled with them to connect with interesting problems that they can be applied to. The absolutely core question for effective 21st Century research communication is how to enable those tools, skillsets, and human energy to be applied to the outputs of research.
I did this on a rainy Saturday afternoon because I could, because it helped me learn a few things, and because it was fun. I’m one of tens or hundreds of thousands who could have done this, who might apply those skills to cleaning up the geocoding of species in research articles, or extracting chemical names, or phylogenetic trees, or finding new ways to understand the networks of influence in the research literature. I’m not going to ask for permission, I’m not going to go out of my way to get access, and I’m not going to build something I’m not allowed to share. A few dedicated individuals will tackle the permissions issues and the politics. The rest will just move on to the next interesting, and more accessible, puzzle.
Traditional publishers actions, whether this access initiative, CHORUS, or their grudging approach to Open Access implementation, consistently focus on retaining absolute control over any potential use of content that might hypothetically be a future revenue source. This means each new means of access, each new form of use, needs to be regulated, controlled and licensed. This is perfectly understandable. It is the logical approach for a business model which is focussed on monetising a monopoly control over pieces of content. It’s just a really bad way of serving the interests of authors in having their work used, enhanced, and integrated into the wider information commons that the rest of the world uses.
