Warnings That Work: Combating Misinformation Without Deplatforming
Freedom to Tinker 2021-07-26
Ben Kaiser, Jonathan Mayer, and J. Nathan Matias
This post originally appeared on Lawfare.
“They’re killing people.” President Biden lambasted Facebook last week for allowing vaccine misinformation to proliferate on its platform. Facebook issued a sharp rejoinder, highlighting the many steps it has taken to promote accurate public health information and expressing angst about government censorship.
Here’s the problem: Both are right. Five years after Russia’s election meddling, and more than a year into the COVID-19 pandemic, misinformation remains far too rampant on social media. But content removal and account deplatforming are blunt instruments fraught with free speech implications. Both President Biden and Facebook have taken steps to dial down the temperature since last week’s dustup, but the fundamental problem remains: How can platforms effectively combat misinformation with steps short of takedowns? As our forthcoming research demonstrates, providing warnings to users can make a big difference, but not all warnings are created equal.
The theory behind misinformation warnings is that if a social media platform provides an informative notice to a user, that user will then make more informed decisions about what information to read and believe. In the terminology of free speech law and policy, warnings could act as a form of counterspeech for misinformation. Facebook recognized as early as 2017 that warnings could alert users to untrustworthy content, provide relevant facts, and give context that helps users avoid being misinformed. Since then, Twitter, YouTube, and other platforms have adopted warnings as a primary tool for responding to misinformation about COVID-19, elections, and other contested topics.
But as academic researchers who study online misinformation, we unfortunately see little evidence that these types of misinformation warnings are working. Study after study has shown minimal effects for common warning designs. In our own laboratory research, appearing at next month’s USENIX Security Symposium, we found that many study participants didn’t even notice typical warnings—and when they did, they ignored the notices. Platforms sometimes claim the warnings work, but the drips of data they’ve released are unconvincing.
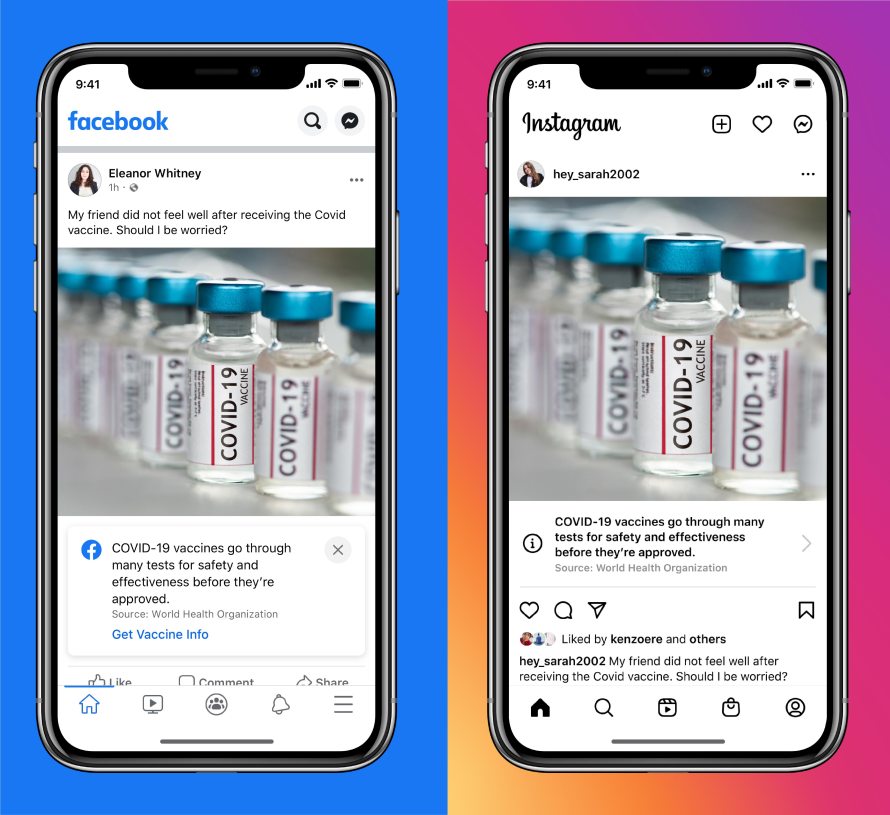
The fundamental problem is that social media platforms rely predominantly on “contextual” warnings, which appear alongside content and provide additional information as context. This is the exact same approach that software vendors initially took 20 years ago with security warnings, and those early warning designs consistently failed to protect users from vulnerabilities, scams, and malware. Researchers eventually realized that not only did contextual warnings fail to keep users safe, but they also formed a barrage of confusing indicators and popups that users learned to ignore or dismiss. Software vendors responded by collaborating closely with academic researchers to refine warnings and converge on measures of success; a decade of effort culminated in modern warnings that are highly effective and protect millions of users from security threats every day.
Social media platforms could have taken a similar approach, with transparent and fast-paced research. If they had, perhaps we would now have effective warnings to curtail the spread of vaccine misinformation. Instead, with few exceptions, platforms have chosen incrementalism over innovation. The latest warnings from Facebook and Twitter, and previews of forthcoming warnings, are remarkably similar in design to warnings Facebook deployed and then discarded four years ago. Like most platform warnings, these designs feature small icons, congenial styling, and discreet placement below offending content.
{kind=link}
When contextual security warnings flopped, especially in web browsers, designers looked for alternatives. The most important development has been a new format of warning that interrupts users’ actions and forces them to make a choice about whether to continue. These “interstitial” warnings are now the norm in web browsers and operating systems.
In our forthcoming publication—a collaboration with Jerry Wei, Eli Lucherini, and Kevin Lee—we aimed to understand how contextual and interstitial disinformation warnings affect user beliefs and information-seeking behavior. We adapted methods from security warnings research, designing two studies where participants completed fact-finding tasks and periodically encountered disinformation warnings. We placed warnings on search results, as opposed to social media posts, to provide participants with a concrete goal (finding information) and multiple pathways to achieve that goal (different search results). This let us measure behavioral effects with two metrics: clickthrough, the rate at which participants bypassed the warnings, and the number of alternative visits, where after seeing a warning, a participant checked at least one more source before submitting an answer.
In the first study, we found that laboratory participants rarely noticed contextual disinformation warnings in Google Search results, and even more rarely took the warnings into consideration. When searching for information, participants overwhelmingly clicked on sources despite contextual warnings, and they infrequently visited alternative sources. In post-task interviews, more than two-thirds of participants told us they didn’t even realize they had encountered a warning.
For our second study, we hypothesized that interstitial warnings could be more effective. We recruited hundreds of participants on Mechanical Turk for another round of fact-finding tasks, this time using a simulated search engine to control the search queries and results. Participants could find the facts by clicking on relevant-looking search results, but they would first be interrupted by an interstitial warning, forcing them to choose whether to continue or go back to the search results.
The results were stunning: Interstitial warnings dramatically changed what users chose to read. Users overwhelmingly noticed the warnings, considered the warnings, and then either declined to read the flagged content or sought out alternative information to verify it. Importantly, users also understood the interstitial warnings. When presented with an explanation in plain language, participants correctly described both why the warning appeared and what risk the warning was highlighting.
Platforms do seem to be—slowly—recognizing the promise of interstitial misinformation warnings. Facebook, Twitter, and Reddit have tested full-page interstitial warnings similar to the security warnings that inspired our work, and the platforms have also deployed other formats of interstitials. The “windowshade” warnings that Instagram pioneered are a particularly thoughtful design. Platforms are plainly searching for misinformation responses that are more effective than contextual warnings but also less problematic than permanent deplatforming. Marjorie Taylor Greene’s vaccine misinformation, for example, recently earned her a brief, 12-hour suspension from Twitter, restrictions on engagement with her tweets, and contextual warnings—an ensemble approach to content moderation.
{kind=link}
But platforms remain extremely tentative with interstitial warnings. For the vast majority of mis- and disinformation that platforms identify, they still either apply tepid contextual warnings or resort to harsher moderation tools like deleting content or banning accounts.
Platforms may be concerned that interstitial warnings are too forceful, and that they go beyond counterspeech by nudging users to avoid misinformation. But the point is to have a spectrum of content moderation tools to respond to the spectrum of harmful content. Contextual warnings may be appropriate for lower-risk misinformation, and deplatforming may be the right move for serial disinformers. Interstitial warnings are a middle-ground option that deserve a place in the content moderation toolbox. Remember last year, when Twitter blocked a New York Post story from being shared because it appeared to be sourced from hacked materials? Amid cries of censorship, Twitter relented and simply labeled the content. An interstitial warning would have straddled that gulf, allowing the content on the platform while still making sure users knew the article was questionable.
What platforms should pursue—and the Biden-Harris administration could constructively encourage—is an agenda of aggressive experimentalism to combat misinformation. Much like software vendors a decade ago, platforms should be rapidly trying out new approaches, publishing lessons learned, and collaborating closely with external researchers. Experimentation can also shed light on why certain warning designs work, informing free speech considerations. Misinformation is a public crisis that demands bold action and platform cooperation. In advancing the science of misinformation warnings, the government and platforms should see an opportunity for common ground.
We thank Alan Rozenshtein, Ross Teixeira and Rushi Shah for valuable suggestions on this piece. All views are our own.