Announcing an automatic theorem proving project
Gowers's Weblog 2022-04-28
I am very happy to say that I have recently received a generous grant from the Astera Institute to set up a small group to work on automatic theorem proving, in the first instance for about three years after which we will take stock and see whether it is worth continuing. This will enable me to take on up to about three PhD students and two postdocs over the next couple of years. I am imagining that two of the PhD students will start next October and that at least one of the postdocs will start as soon as is convenient for them. Before any of these positions are advertised, I welcome any informal expressions of interest: in the first instance you should email me, and maybe I will set up Zoom meetings. (I have no idea what the level of demand is likely to be, so exactly how I respond to emails of this kind will depend on how many of them there are.)
I have privately let a few people know about this, and as a result I know of a handful of people who are already in Cambridge and are keen to participate. So I am expecting the core team working on the project to consist of 6-10 people. But I also plan to work in as open a way as possible, in the hope that people who want to can participate in the project remotely even if they are not part of the group that is based physically in Cambridge. Thus, part of the plan is to report regularly and publicly on what we are thinking about, what problems, both technical and more fundamental, are holding us up, and what progress we make. Also, my plan at this stage is that any software associated with the project will be open source, and that if people want to use ideas generated by the project to incorporate into their own theorem-proving programs, I will very much welcome that.
I have written a 54-page document that explains in considerable detail what the aims and approach of the project will be. I would urge anyone who thinks they might want to apply for one of the positions to read it first — not necessarily every single page, but enough to get a proper understanding of what the project is about. Here I will explain much more briefly what it will be trying to do, and what will set it apart from various other enterprises that are going on at the moment.
In brief, the approach taken will be what is often referred to as a GOFAI approach, where GOFAI stands for “good old-fashioned artificial intelligence”. Roughly speaking, the GOFAI approach to artificial intelligence is to try to understand as well as possible how humans achieve a particular task, and eventually reach a level of understanding that enables one to program a computer to do the same.
As the phrase “old-fashioned” suggests, GOFAI has fallen out of favour in recent years, and some of the reasons for that are good ones. One reason is that after initial optimism, progress with that approach stalled in many domains of AI. Another is that with the rise of machine learning it has become clear that for many tasks, especially pattern-recognition tasks, it is possible to program a computer to do them very well without having a good understanding of how humans do them. For example, we may find it very difficult to write down a set of rules that distinguishes between an array of pixels that represents a dog and an array of pixels that represents a cat, but we can still train a neural network to do the job.
However, while machine learning has made huge strides in many domains, it still has several areas of weakness that are very important when one is doing mathematics. Here are a few of them.
- In general, tasks that involve reasoning in an essential way.
- Learning to do one task and then using that ability to do another.
- Learning based on just a small number of examples.
- Common sense reasoning.
- Anything that involves genuine understanding (even if it may be hard to give a precise definition of what understanding is) as opposed to sophisticated mimicry.
Obviously, researchers in machine learning are working in all these areas, and there may well be progress over the next few years, but for the time being there are still significant limitations to what machine learning can do. (Two people who have written very interestingly on these limitations are Melanie Mitchell and François Chollet.)
That said, using machine learning techniques in automatic theorem proving is a very active area of research at the moment. (Two names you might like to look up if you want to find out about this area are Christian Szegedy and Josef Urban.) The project I am starting will not be a machine-learning project, but I think there is plenty of potential for combining machine learning with GOFAI ideas — for example, one might use GOFAI to reduce the options for what the computer will do next to a small set and use machine learning to choose the option out of that small set — so I do not rule out some kind of wider collaboration once the project has got going.
Another area that is thriving at the moment is formalization. Over the last few years, several major theorems and definitions have been fully formalized that would have previously seemed out of reach — examples include Gödel’s theorem, the four-colour theorem, Hales’s proof of the Kepler conjecture, Thompson’s odd-order theorem, and a lemma of Dustin Clausen and Peter Scholze with a proof that was too complicated for them to be able to feel fully confident that it was correct. That last formalization was carried out in Lean by the exciting group that is led by Kevin Buzzard.
As with machine learning, I mention formalization in order to contrast it with the project I am announcing here. It may seem slightly negative to focus on what it will not be doing, but I feel it is important, because I do not want to attract applications from people who have an incorrect picture of what they would be doing. Also as with machine learning, I would welcome and even expect collaboration with the Lean group. For us it would be potentially very interesting to make use of the Lean database of results, and it would also be nice (even if not essential) to have output that is formalized using a standard system. And we might be able to contribute to the Lean enterprise by creating code that performs steps automatically that are currently done by hand. A very interesting looking new institute, the Hoskinson Center for Formal Mathematics, has recently been set up with Jeremy Avigad at the helm, which will almost certainly make such collaborations easier.
But now let me turn to the kinds of things I hope this project will do.
Why is mathematics easy?
Ever since Turing, we have known that there is no algorithm that will take as input a mathematical statement and output a proof if the statement has a proof or the words “this statement does not have a proof” otherwise. (If such an algorithm existed, one could feed it statements of the form “algorithm A halts” and the halting problem would be solved.) If 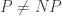
The broad answer is that while the theoretical results just alluded to show that we cannot expect to determine the proof status of arbitrary mathematical statements, that is not what we try to do. Rather, we look at only a tiny fraction of well-formed statements, and the kinds of proofs we find tend to have a lot more structure than is guaranteed by the formal definition of a proof as a sequence of statements, each of which is either an initial assumption or follows in a simple way from earlier statements. (It is interesting to speculate about whether there are, out there, utterly bizarre and idea-free proofs that just happen to establish concise mathematical statements but that will never be discovered because searching for them would take too long.) A good way of thinking about this project is that it will be focused on the following question.
Question. What is it about the proofs that mathematicians actually find that makes them findable in a reasonable amount of time?
Clearly, a good answer to this question would be extremely useful for the purposes of writing automatic theorem proving programs. Equally, any advances in a GOFAI approach to writing automatic theorem proving programs have the potential to feed into an answer to the question. I don’t have strong views about the right balance between the theoretical and practical sides of the project, but I do feel strongly that both sides should be major components of it.
The practical side of the project will, at least to start with, be focused on devising algorithms that find proofs in a way that imitates as closely as possible how humans find them. One important aspect of this is that I will not be satisfied with programs that find proofs after carrying out large searches, even if those searches are small enough to be feasible. More precisely, searches will be strongly discouraged unless human mathematicians would also need to do them. A question that is closely related to the question above is the following, which all researchers in automatic theorem proving have to grapple with.
Question. Humans seem to be able to find proofs with a remarkably small amount of backtracking. How do they prune the search tree to such an extent?
Allowing a program to carry out searches of “silly” options that humans would never do is running away from this absolutely central question.
With Mohan Ganesalingam, Ed Ayers and Bhavik Mehta (but not simultaneously), I have over the years worked on writing theorem-proving programs with as little search as possible. This will provide a starting point for the project. One of the reasons I am excited to have the chance to set up a group is that I have felt for a long time that with more people working on the project, there is a chance of much more rapid progress — I think the progress will scale up more than linearly in the number of people, at least up to a certain size. And if others were involved round the world, I don’t think it is unreasonable to hope that within a few years there could be theorem-proving programs that were genuinely useful — not necessarily at a research level but at least at the level of a first-year undergraduate. (To be useful a program does not have to be able to solve every problem put in front of it: even a program that could solve only fairly easy problems but in a sufficiently human way that it could explain how it came up with its proofs could be a very valuable educational tool.)
A more distant dream is of course to get automatic theorem provers to the point where they can solve genuinely difficult problems. Something else that I would like to see coming out of this project is a serious study of how humans do this. From time to time I have looked at specific proofs that appear to require at a certain point an idea that comes out of nowhere, and after thinking very hard about them I have eventually managed to present a plausible account of how somebody might have had the idea, which I think of as a “justified proof”. I would love it if there were a large collection of such accounts, and I have it in mind as a possible idea to set up (with help) a repository for them, though I would need to think rather hard about how best to do it. One of the difficulties is that whereas there is widespread agreement about what constitutes a proof, there is not such a clear consensus about what constitutes a convincing explanation of where an idea comes from. Another theoretical problem that interests me a lot is the following.
Problem. Come up with a precise definition of a “proof justification”.
Though I do not have a satisfactory definition, very recently I have had some ideas that will I think help to narrow down the search substantially. I am writing these ideas down and hope to make them public soon.
Who am I looking for?
There is much more I could say about the project, but if this whets your appetite, then I refer you to the document where I have said much more about it. For the rest of this post I will say a little bit more about the kind of person I am looking for and how a typical week might be spent.
The most important quality I am looking for in an applicant for a PhD or postdoc associated with this project is a genuine enthusiasm for the GOFAI approach briefly outlined here and explained in more detail in the much longer document. If you read that document and think that that is the kind of work you would love to do and would be capable of doing, then that is a very good sign. Throughout the document I give indications of things that I don’t yet know how to do. If you find yourself immediately drawn into thinking about those problems, which range from small technical problems to big theoretical questions such as the ones mentioned above, then that is even better. And if you are not fully satisfied with a proof unless you can see why it was natural for somebody to think of it, then that is better still.
I would expect a significant proportion of people reading the document to have an instinctive reaction that the way I propose to attack the problems is not the best way, and that surely one should use some other technique — machine learning, large search, the Knuth-Bendix algorithm, a computer algebra package, etc. etc. — instead. If that is your reaction, then the project probably isn’t a good fit for you, as the GOFAI approach is what it is all about.
As far as qualifications are concerned, I think the ideal candidate is somebody with plenty of experience of solving mathematical problems (either challenging undergraduate-level problems for a PhD candidate or research-level problems for a postdoc candidate), and good programming ability. But if I had to choose one of the two, I would pick the former over the latter, provided that I could be convinced that a candidate had a deep understanding of what a well-designed algorithm would look like. (I myself am not a fluent programmer — I have some experience of Haskell and Python and I think a pretty good feel for how to specify an algorithm in a way that makes it implementable by somebody who is a quick coder, and in my collaborations so far have relied on my collaborators to do the coding.) Part of the reason for that is that I hope that if one of the outputs of the group is detailed algorithm designs, then there will be remote participants who would enjoy turning those designs into code.
How will the work be organized?
The core group is meant to be a genuine team rather than simply a group of a few individuals with a common interest in automatic theorem proving. To this end, I plan that the members of the group will meet regularly — I imagine something like twice a week for at least two hours and possibly more — and will keep in close contact, and very likely meet less formally outside those meetings. The purpose of the meetings will be to keep the project appropriately focused. That is not to say that all team members will work on the same narrow aspect of the problem at the same time. However, I think that with a project like this it will be beneficial (i) to share ideas frequently, (ii) to keep thinking strategically about how to get the maximum expected benefit for the effort put in , and (iii) to keep updating our public list of open questions (which will not be open questions in the usual mathematical sense, but questions more like “How should a computer do this?” or “Why is it so obvious to a human mathematician that this would be a silly thing to try?”).
In order to make it easy for people to participate remotely, I think probably we will want to set up a dedicated website where people can post thoughts, links to code, questions, and so on. Some thought will clearly need to go into how best to design such a site, and help may be needed to build it, which if necessary I could pay for. Another possibility would of course be to have Zoom meetings, but whether or not I would want to do that depends somewhat on who ends up participating and how they do so.
Since the early days of Polymath I have become much more conscious that merely stating that a project is open to anybody who wishes to join in does not automatically make it so. For example, whereas I myself am comfortable with publicly suggesting a mathematical idea that turns out on further reflection to be fruitless or even wrong, many people are, for very good reasons, not willing to do so, and those people belong disproportionately to groups that have been historically marginalized from mathematics — which of course is not a coincidence. Because of this, I have not yet decided on the details of how remote participation might work. Maybe part of it could be fully open in the way that Polymath was, but part of it could be more private and carefully moderated. Or perhaps separate groups could be set up that communicated regularly with the Cambridge group. There are many possibilities, but which ones would work best depends on who is interested. If you are interested in the project but would feel excluded by certain modes of participation, then please get in touch with me and we can think about what would work for you.