Tim Gowers, Ben Green, Freddie Manners, and I have just uploaded to the arXiv our paper “Marton’s conjecture in abelian groups with bounded torsion“. This paper fully resolves a conjecture of Katalin Marton (the bounded torsion case of the Polynomial Freiman–Ruzsa conjecture (first proposed by Katalin Marton):
Theorem 1 (Marton’s conjecture) Let  be an abelian
be an abelian  -torsion group (thus,
-torsion group (thus, 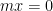 for all
for all  ), and let
), and let 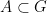 be such that
be such that 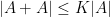 . Then
. Then  can be covered by at most
can be covered by at most 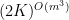 translates of a subgroup
translates of a subgroup  of
of  of cardinality at most
of cardinality at most 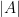 . Moreover, is contained in
. Moreover, is contained in  for some
for some 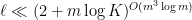 .
.
We had previously established the 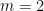 case of this result, with the number of translates bounded by
case of this result, with the number of translates bounded by 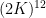 (which was subsequently improved to
(which was subsequently improved to  by Jyun-Jie Liao), but without the additional containment
by Jyun-Jie Liao), but without the additional containment  . It remains a challenge to replace
. It remains a challenge to replace  by a bounded constant (such as
by a bounded constant (such as  ); this is essentially the “polynomial Bogulybov conjecture”, which is still open. The result has been formalized in the proof assistant language Lean, as discussed in this previous blog post. As a consequence of this result, many of the applications of the previous theorem may now be extended from characteristic to higher characteristic. Our proof techniques are a modification of those in our previous paper, and in particular continue to be based on the theory of Shannon entropy. For inductive purposes, it turns out to be convenient to work with the following version of the conjecture (which, up to -dependent constants, is actually equivalent to the above theorem):
); this is essentially the “polynomial Bogulybov conjecture”, which is still open. The result has been formalized in the proof assistant language Lean, as discussed in this previous blog post. As a consequence of this result, many of the applications of the previous theorem may now be extended from characteristic to higher characteristic. Our proof techniques are a modification of those in our previous paper, and in particular continue to be based on the theory of Shannon entropy. For inductive purposes, it turns out to be convenient to work with the following version of the conjecture (which, up to -dependent constants, is actually equivalent to the above theorem):
Theorem 2 (Marton’s conjecture, entropy form) Let be an abelian -torsion group, and let  be independent finitely supported random variables on , such that
be independent finitely supported random variables on , such that
![\displaystyle {\bf H}[X_1+\dots+X_m] - \frac{1}{m} \sum_{i=1}^m {\bf H}[X_i] \leq \log K,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_1%2B%5Cdots%2BX_m%5D+-+%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5Em+%7B%5Cbf+H%7D%5BX_i%5D+%5Cleq+%5Clog+K%2C&bg=ffffff&fg=000000&s=0&c=20201002)
where 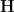 denotes Shannon entropy. Then there is a uniform random variable
denotes Shannon entropy. Then there is a uniform random variable 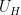 on a subgroup of such that
on a subgroup of such that
![\displaystyle \frac{1}{m} \sum_{i=1}^m d[X_i; U_H] \ll m^3,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5Em+d%5BX_i%3B+U_H%5D+%5Cll+m%5E3%2C&bg=ffffff&fg=000000&s=0&c=20201002)
where  denotes the entropic Ruzsa distance (see previous blog post for a definition); furthermore, if all the
denotes the entropic Ruzsa distance (see previous blog post for a definition); furthermore, if all the  take values in some symmetric set
take values in some symmetric set  , then lies in
, then lies in  for some
for some  .
.
As a first approximation, one should think of all the as identically distributed, and having the uniform distribution on , as this is the case that is actually relevant for implying Theorem 1; however, the recursive nature of the proof of Theorem 2 requires one to manipulate the separately. It also is technically convenient to work with independent variables, rather than just a pair of variables as we did in the case; this is perhaps the biggest additional technical complication needed to handle higher characteristics. The strategy, as with the previous paper, is to attempt an entropy decrement argument: to try to locate modifications 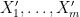 of that are reasonably close (in Ruzsa distance) to the original random variables, while decrementing the “multidistance”
of that are reasonably close (in Ruzsa distance) to the original random variables, while decrementing the “multidistance”
![\displaystyle {\bf H}[X_1+\dots+X_m] - \frac{1}{m} \sum_{i=1}^m {\bf H}[X_i]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_1%2B%5Cdots%2BX_m%5D+-+%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi%3D1%7D%5Em+%7B%5Cbf+H%7D%5BX_i%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
which turns out to be a convenient metric for progress (for instance, this quantity is non-negative, and vanishes if and only if the are all translates of a uniform random variable on a subgroup ). In the previous paper we modified the corresponding functional to minimize by some additional terms in order to improve the exponent 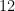 , but as we are not attempting to completely optimize the constants, we did not do so in the current paper (and as such, our arguments here give a slightly different way of establishing the case, albeit with somewhat worse exponents). As before, we search for such improved random variables by introducing more independent random variables – we end up taking an array of
, but as we are not attempting to completely optimize the constants, we did not do so in the current paper (and as such, our arguments here give a slightly different way of establishing the case, albeit with somewhat worse exponents). As before, we search for such improved random variables by introducing more independent random variables – we end up taking an array of  random variables
random variables  for
for 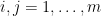 , with each a copy of , and forming various sums of these variables and conditioning them against other sums. Thanks to the magic of Shannon entropy inequalities, it turns out that it is guaranteed that at least one of these modifications will decrease the multidistance, except in an “endgame” situation in which certain random variables are nearly (conditionally) independent of each other, in the sense that certain conditional mutual informations are small. In particular, in the endgame scenario, the row sums
, with each a copy of , and forming various sums of these variables and conditioning them against other sums. Thanks to the magic of Shannon entropy inequalities, it turns out that it is guaranteed that at least one of these modifications will decrease the multidistance, except in an “endgame” situation in which certain random variables are nearly (conditionally) independent of each other, in the sense that certain conditional mutual informations are small. In particular, in the endgame scenario, the row sums 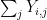 of our array will end up being close to independent of the column sums
of our array will end up being close to independent of the column sums 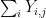 , subject to conditioning on the total sum
, subject to conditioning on the total sum  . Not coincidentally, this type of conditional independence phenomenon also shows up when considering row and column sums of iid independent gaussian random variables, as a specific feature of the gaussian distribution. It is related to the more familiar observation that if
. Not coincidentally, this type of conditional independence phenomenon also shows up when considering row and column sums of iid independent gaussian random variables, as a specific feature of the gaussian distribution. It is related to the more familiar observation that if  are two independent copies of a Gaussian random variable, then
are two independent copies of a Gaussian random variable, then 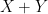 and
and 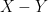 are also independent of each other. Up until now, the argument does not use the -torsion hypothesis, nor the fact that we work with an
are also independent of each other. Up until now, the argument does not use the -torsion hypothesis, nor the fact that we work with an 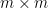 array of random variables as opposed to some other shape of array. But now the torsion enters in a key role, via the obvious identity
array of random variables as opposed to some other shape of array. But now the torsion enters in a key role, via the obvious identity

In the endgame, the any pair of these three random variables are close to independent (after conditioning on the total sum ). Applying some “entropic Ruzsa calculus” (and in particular an entropic version of the Balog–Szeméredi–Gowers inequality), one can then arrive at a new random variable  of small entropic doubling that is reasonably close to all of the in Ruzsa distance, which provides the final way to reduce the multidistance. Besides the polynomial Bogulybov conjecture mentioned above (which we do not know how to address by entropy methods), the other natural question is to try to develop a characteristic zero version of this theory in order to establish the polynomial Freiman–Ruzsa conjecture over torsion-free groups, which in our language asserts (roughly speaking) that random variables of small entropic doubling are close (in Ruzsa distance) to a discrete Gaussian random variable, with good bounds. The above machinery is consistent with this conjecture, in that it produces lots of independent variables related to the original variable, various linear combinations of which obey the same sort of entropy estimates that gaussian random variables would exhibit, but what we are missing is a way to get back from these entropy estimates to an assertion that the random variables really are close to Gaussian in some sense. In continuous settings, Gaussians are known to extremize the entropy for a given variance, and of course we have the central limit theorem that shows that averages of random variables typically converge to a Gaussian, but it is not clear how to adapt these phenomena to the discrete Gaussian setting (without the circular reasoning of assuming the polynoimal Freiman–Ruzsa conjecture to begin with).
of small entropic doubling that is reasonably close to all of the in Ruzsa distance, which provides the final way to reduce the multidistance. Besides the polynomial Bogulybov conjecture mentioned above (which we do not know how to address by entropy methods), the other natural question is to try to develop a characteristic zero version of this theory in order to establish the polynomial Freiman–Ruzsa conjecture over torsion-free groups, which in our language asserts (roughly speaking) that random variables of small entropic doubling are close (in Ruzsa distance) to a discrete Gaussian random variable, with good bounds. The above machinery is consistent with this conjecture, in that it produces lots of independent variables related to the original variable, various linear combinations of which obey the same sort of entropy estimates that gaussian random variables would exhibit, but what we are missing is a way to get back from these entropy estimates to an assertion that the random variables really are close to Gaussian in some sense. In continuous settings, Gaussians are known to extremize the entropy for a given variance, and of course we have the central limit theorem that shows that averages of random variables typically converge to a Gaussian, but it is not clear how to adapt these phenomena to the discrete Gaussian setting (without the circular reasoning of assuming the polynoimal Freiman–Ruzsa conjecture to begin with).