I’ve just uploaded to the arXiv my paper “Dense sets of natural numbers with unusually large least common multiples“. This short paper answers (in the negative) a somewhat obscure question of Erdös and Graham:
Problem 1 Is it true that if  is a set of natural numbers for which
is a set of natural numbers for which 
goes to infinity as  , then the quantity
, then the quantity 
also goes to infinity as ?
At first glance, this problem may seem rather arbitrary, but it can be motivated as follows. The hypothesis that (1) goes to infinity is a largeness condition on ; in view of Mertens’ theorem, it can be viewed as an assertion that is denser than the set of primes. On the other hand, the conclusion that (2) grows is an assertion that  becomes significantly smaller than
becomes significantly smaller than  on the average for large
on the average for large  ; that is to say, that many pairs of numbers in share a common factor. Intuitively, the problem is then asking whether sets that are significantly denser than the primes must start having lots of common factors on average.
; that is to say, that many pairs of numbers in share a common factor. Intuitively, the problem is then asking whether sets that are significantly denser than the primes must start having lots of common factors on average.
For sake of comparison, it is easy to see that if (1) goes to infinity, then at least one pair 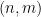 of distinct elements in must have a non-trivial common factor. For if this were not the case, then the elements of are pairwise coprime, so each prime
of distinct elements in must have a non-trivial common factor. For if this were not the case, then the elements of are pairwise coprime, so each prime  has at most one multiple in , and so can contribute at most
has at most one multiple in , and so can contribute at most 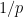 to the sum in (1), and hence by Mertens’ theorem, and the fact that every natural number greater than one is divisible by at least one prime , the quantity (1) stays bounded, a contradiction.
to the sum in (1), and hence by Mertens’ theorem, and the fact that every natural number greater than one is divisible by at least one prime , the quantity (1) stays bounded, a contradiction.
It turns out, though, that the answer to the above problem is negative; one can find sets that are denser than the primes, but for which (2) stays bounded, so that the least common multiples in the set are unusually large. It was a bit surprising to me that this question had not been resolved long ago (in fact, I was not able to find any prior literature on the problem beyond the original reference of Erdös and Graham); in contrast, another problem of Erdös and Graham concerning sets with unusually small least common multiples was extensively studied (and essentially solved) about twenty years ago, while the study of sets with unusually large greatest common divisor for many pairs in the set has recently become somewhat popular, due to their role in the proof of the Duffin-Schaeffer conjecture by Koukoulopoulos and Maynard.
To search for counterexamples, it is natural to look for numbers with relatively few prime factors, in order to reduce their common factors and increase their least common multiple. A particularly simple example, whose verification is on the level of an exercise in a graduate analytic number theory course, is the set of semiprimes (products of two primes), for which one can readily verify that (1) grows like 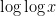 but (2) stays bounded. With a bit more effort, I was able to optimize the construction and uncover the true threshold for boundedness of (2), which was a little unexpected:
but (2) stays bounded. With a bit more effort, I was able to optimize the construction and uncover the true threshold for boundedness of (2), which was a little unexpected:
Theorem 2
The proofs are not particularly long or deep, but I thought I would record here some of the process towards finding them. My first step was to try to simplify the condition that (2) stays bounded. In order to use probabilistic intuition, I first expressed this condition in probabilistic terms as

for large

, where

are independent random variables drawn from

with probability density function

The presence of the least common multiple in the denominator is annoying, but one can easily flip the expression to the greatest common divisor:

If the expression

was a product of a function of
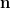
and a function of

, then by independence this expectation would decouple into simpler averages involving just one random variable instead of two. Of course, the greatest common divisor is not of this form, but there is a standard trick in analytic number theory to decouple the greatest common divisor, namely to use the classic Gauss identity

, with
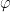
the <a href="
https://en.wikipedia.org/wiki/Euler 
Inserting this formula and interchanging the sum and expectation, we can now express the condition as bounding a sum of squares:

Thus, the condition \eqref”> is really an assertion to the effect that typical elements of
do not have many divisors. From experience in sieve theory, the probabilities

tend to behave multiplicatively in

, so the expression here heuristically behaves like an Euler product that looks something like

and so the condition \eqref. Standard methods from the anatomy of integers can then be used to see how dense a set with that many prime factors could be, and this soon led to a short proof of part (ii) of the main theorem (I eventually found for instance that Jensen’s inequality could be used to create a particularly slick argument).
It then remained to improve the lower bound construction to eliminate the  losses in the exponents. By deconstructing the proof of the upper bound, it became natural to consider something like the set of natural numbers
losses in the exponents. By deconstructing the proof of the upper bound, it became natural to consider something like the set of natural numbers  that had at most
that had at most  prime factors. This construction actually worked for some scales – namely those for which
prime factors. This construction actually worked for some scales – namely those for which  was a natural number – but there was some strange “discontinuities” in the analysis that prevented me from establishing the boundedness of (2) for arbitrary scales . The basic problem was that increasing the number of permitted prime factors from one natural number threshold
was a natural number – but there was some strange “discontinuities” in the analysis that prevented me from establishing the boundedness of (2) for arbitrary scales . The basic problem was that increasing the number of permitted prime factors from one natural number threshold  to another
to another  ended up increasing the density of the set by an unbounded factor (of the order of , in practice), which heavily disrupted the task of trying to keep the ratio (2) bounded. Usually the resolution to these sorts of discontinuities is to use some sort of random “average” of two or more deterministic constructions – for instance, by taking some random union of some numbers with prime factors and some numbers with prime factors – but the numerology turned out to be somewhat unfavorable, allowing for some improvement in the lower bounds over my previous construction, but not enough to close the gap entirely. It was only after substantial trial and error that I was able to find a working deterministic construction, where at a given scale one collected either numbers with at most prime factors, or numbers with prime factors but with the largest prime factor in a specific range, in which I could finally get the numerator and denominator in (2) to be in balance for every . But once the construction was written down, the verification of the required properties ended up being quite routine.
ended up increasing the density of the set by an unbounded factor (of the order of , in practice), which heavily disrupted the task of trying to keep the ratio (2) bounded. Usually the resolution to these sorts of discontinuities is to use some sort of random “average” of two or more deterministic constructions – for instance, by taking some random union of some numbers with prime factors and some numbers with prime factors – but the numerology turned out to be somewhat unfavorable, allowing for some improvement in the lower bounds over my previous construction, but not enough to close the gap entirely. It was only after substantial trial and error that I was able to find a working deterministic construction, where at a given scale one collected either numbers with at most prime factors, or numbers with prime factors but with the largest prime factor in a specific range, in which I could finally get the numerator and denominator in (2) to be in balance for every . But once the construction was written down, the verification of the required properties ended up being quite routine.
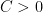 , there exists a set of natural numbers
, there exists a set of natural numbers 
