What are the odds, II: the Venezuelan presidential election
What's new 2024-08-02
In a previous blog post, I discussed how, from a Bayesian perspective, learning about some new information 

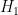


- (i) A precise formulation of the null hypothesis
- (ii) A reasonable estimate of the prior odds
- (iii) A reasonable estimate of the probability
that the event
- (iv) A reasonable estimate of the probability
that the event
 of the alternative hypothesis being true after observing the event . Ingredient (iii) is usually the easiest to compute, but is only one of the key inputs required; ingredients (ii) and (iv) are far trickier, involve subjective non-mathematical considerations, and as discussed in the previous post, depend rather crucially on ingredient (i). For instance, selectively reporting some relevant information for , and witholding other key information from , can make the final mathematical calculation misleading with regard to the “true” odds of being true compared to based on all available information, even if the calculation was technically accurate with regards to the partial information provided. Also, the computation of the relative odds of two competing hypotheses and can become somewhat moot if there is a third hypothesis
of the alternative hypothesis being true after observing the event . Ingredient (iii) is usually the easiest to compute, but is only one of the key inputs required; ingredients (ii) and (iv) are far trickier, involve subjective non-mathematical considerations, and as discussed in the previous post, depend rather crucially on ingredient (i). For instance, selectively reporting some relevant information for , and witholding other key information from , can make the final mathematical calculation misleading with regard to the “true” odds of being true compared to based on all available information, even if the calculation was technically accurate with regards to the partial information provided. Also, the computation of the relative odds of two competing hypotheses and can become somewhat moot if there is a third hypothesis 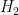 that ends up being more plausible than either of these two hypotheses. Nevertheless, the formula (1) can still lead to useful conclusions, albeit ones that are qualified by the particular assumptions and estimates made in the analysis.
that ends up being more plausible than either of these two hypotheses. Nevertheless, the formula (1) can still lead to useful conclusions, albeit ones that are qualified by the particular assumptions and estimates made in the analysis. At a qualitative level, the Bayesian identity (1) is telling us the following: if an alternative hypothesis
In the previous blog post, this calculation was initially illustrated with the following choices of
-
(that is to say, consecutive multiples if
), though not necessarily in that order;
-
; and
-
 is much larger than the tiny probability (2), and in fact it could well be smaller (since would likely be in the interest of corrupt lottery officials to not draw attention to their activities). So, despite the very small numerical value of the probability (2), this did not lead to any significant increase in the odds of the alternative hypothesis. In the previous blog post, several other variants
is much larger than the tiny probability (2), and in fact it could well be smaller (since would likely be in the interest of corrupt lottery officials to not draw attention to their activities). So, despite the very small numerical value of the probability (2), this did not lead to any significant increase in the odds of the alternative hypothesis. In the previous blog post, several other variants 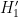 ,
, 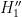 ,
, 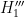 of the alternative hypothesis were also discussed; the conclusion was that while some choices of alternative hypothesis could lead to elevated probabilities for ingredient (iv), they came at the cost of significantly reducing the prior odds in ingredient (ii), and so no alternative hypothesis was located which ended up being significantly more plausible than the null hypothesis after observing the event .
of the alternative hypothesis were also discussed; the conclusion was that while some choices of alternative hypothesis could lead to elevated probabilities for ingredient (iv), they came at the cost of significantly reducing the prior odds in ingredient (ii), and so no alternative hypothesis was located which ended up being significantly more plausible than the null hypothesis after observing the event .In this post, I would like to run the same analysis on a numerical anomaly in the recent Venezuelan presidential election of June 28, 2024. Here are the officially reported vote totals for the two main candidates, incumbent president Nicolás Maduro and opposition candidate Edmundo Gonzáles, in the election:
- Maduro: 5,150,092 votes
- Gonzáles: 4,445,978 votes
- Other: 462,704 votes
- Total: 10,058,774 votes.
 by the round percentages
by the round percentages  ,
,  ,
, 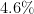 , one recovers exactly the above vote counts after rounding to the nearest integer:
, one recovers exactly the above vote counts after rounding to the nearest integer: 


Let us try to apply the above Bayesian framework to this situation, bearing in mind the caveats that this analysis is only strong as the inputs supplied and assumptions made (for instance, to simplify the discussion, we will not also discuss information from exit polling, which in this case gave significantly different predictions from the percentages above).
The first step (ingredient (i)) is to formulate the null hypothesis
-
).
-
-
Ingredient (ii) – the prior odds that ![{[p-\varepsilon,p+\varepsilon] \times [q-\varepsilon,q+\varepsilon]}](https://s0.wp.com/latex.php?latex=%7B%5Bp-%5Cvarepsilon%2Cp%2B%5Cvarepsilon%5D+%5Ctimes+%5Bq-%5Cvarepsilon%2Cq%2B%5Cvarepsilon%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
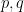








 , the probability that the event would occur under the alternative hypothesis . Here one has to be careful, because while it could happen under hypothesis that the vote counts were manipulated to be exactly the nearest integer to a round percentage, this is not the only outcome under this hypothesis, and indeed one could argue that it would not be in the interest of an administration to generate such a striking numerical anomaly. But one can create a reasonable chain of events with which to estimate (from below) this probability by a kind of “Drake equation“. Consider the following variants of :
, the probability that the event would occur under the alternative hypothesis . Here one has to be careful, because while it could happen under hypothesis that the vote counts were manipulated to be exactly the nearest integer to a round percentage, this is not the only outcome under this hypothesis, and indeed one could argue that it would not be in the interest of an administration to generate such a striking numerical anomaly. But one can create a reasonable chain of events with which to estimate (from below) this probability by a kind of “Drake equation“. Consider the following variants of : -
-
of voters, and rounding to the nearest integer, without any attempt to disguise their actions.


 will likely depend on the individual making this calculation, and will not be discussed further here. The remaining question then is how large the probabilities
will likely depend on the individual making this calculation, and will not be discussed further here. The remaining question then is how large the probabilities  ,
,  , and
, and  are. In other words:
are. In other words: - If one assumes that the administration wishes to manipulate the vote totals, how likely is it a priori (i.e., without being aware of the anomaly
- If one assumes that election officials are being ordered to report vote totals to reflect a preferred round percentage, how likely is it a priori that they would follow the orders without question, and performing simple rounding instead of any more sophisticated numerical manipulation?
- If one assumes that election officials did indeed follow the orders as above, how likely is it a priori that the report would be published as is without any concerns raised by other officials or observers?
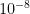 , then we can conclude that the event has indeed significantly raised the odds of some sort of voting manipulation present. The scenario described above is somewhat plausible, especially in light of the anomaly , and so certainly the posterior probabilities
, then we can conclude that the event has indeed significantly raised the odds of some sort of voting manipulation present. The scenario described above is somewhat plausible, especially in light of the anomaly , and so certainly the posterior probabilities  ,
,  seem quite large (and the posterior probability
seem quite large (and the posterior probability  is of course equal to ). But it is important here to avoid confirmation bias and work only with a priori probabilities – roughly speaking, the probabilities that one would assign to such events on July 27, 2024, before knowledge of the anomaly came to light. Nevertheless, even after accounting for confirmation bias, I think it is plausible that the above product of a priori probabilities is indeed significantly larger than (for instance, to assign probabilities somewhat randomly, this would be the case of each of the conditional probabilities , and all exceed
is of course equal to ). But it is important here to avoid confirmation bias and work only with a priori probabilities – roughly speaking, the probabilities that one would assign to such events on July 27, 2024, before knowledge of the anomaly came to light. Nevertheless, even after accounting for confirmation bias, I think it is plausible that the above product of a priori probabilities is indeed significantly larger than (for instance, to assign probabilities somewhat randomly, this would be the case of each of the conditional probabilities , and all exceed  ), giving credence to the theory of the election report being manipulated (though it is possible that the manipulation could occur through a third hypothesis not covered by the original two hypotheses, such as a software glitch). If one adds in additional information beyond the purely numerical anomaly , such as the fact that the reported totals were not broken down further by voting district (which would be less likely under hypothesis than hypothesis ), and that exit polls gave significantly different results from the reported totals (which is again less likely under hypothesis than hypothesis ), the evidence for voting irregularities becomes quite significant.
), giving credence to the theory of the election report being manipulated (though it is possible that the manipulation could occur through a third hypothesis not covered by the original two hypotheses, such as a software glitch). If one adds in additional information beyond the purely numerical anomaly , such as the fact that the reported totals were not broken down further by voting district (which would be less likely under hypothesis than hypothesis ), and that exit polls gave significantly different results from the reported totals (which is again less likely under hypothesis than hypothesis ), the evidence for voting irregularities becomes quite significant.One can contrast this analysis with that of the Phillipine lottery in the original post. In both cases the probability 