Pointwise convergence of bilinear polynomial averages over the primes
What's new 2024-09-17
Ben Krause, Hamed Mousavi, Joni Teräväinen, and I have just uploaded to the arXiv the paper “Pointwise convergence of bilinear polynomial averages over the primes“. This paper builds upon a previous result of Krause, Mirek, and myself, in which we demonstrated the pointwise almost everywhere convergence of the ergodic averages
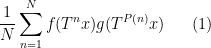
 and almost all
and almost all 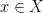 , whenever
, whenever 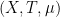 is a measure-preserving system (not necessarily of finite measure), and
is a measure-preserving system (not necessarily of finite measure), and 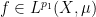 ,
, 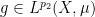 for some
for some 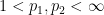 with
with 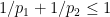 , where
, where  is a polynomial with integer coefficients and degree at least two. Here we establish the prime version of this theorem, that is to say we establish the pointwise almost everywhere convergence of the averages
is a polynomial with integer coefficients and degree at least two. Here we establish the prime version of this theorem, that is to say we establish the pointwise almost everywhere convergence of the averages 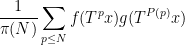 ,
, 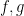 . By standard arguments this is equivalent to the pointwise almost everywhere convergence of the weighted averages
. By standard arguments this is equivalent to the pointwise almost everywhere convergence of the weighted averages 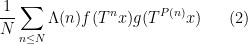
 is the von Mangoldt function. Our argument also borrows from results in a recent paper of Teräväinen, who showed (among other things) that the similar averages
is the von Mangoldt function. Our argument also borrows from results in a recent paper of Teräväinen, who showed (among other things) that the similar averages 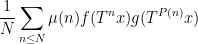
 is assumed to be finite measure. Here of course
is assumed to be finite measure. Here of course  denotes the Möbius function.
denotes the Möbius function.The basic strategy is to try to insert the weight
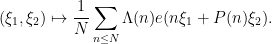
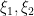 were “major arc”, at which point this symbol could be approximated by a more tractable symbol. Setting aside the Peluse-Prendiville step for now, the first obstacle is that the natural approximation to the symbol does not have sufficiently accurate error bounds if a Siegel zero exists. While one could in principle fix this by adding a Siegel correction term to the approximation, we found it simpler to use the arguments of Teräväinen to essentially replace the von Mangoldt weight by a “Cramér approximant”
were “major arc”, at which point this symbol could be approximated by a more tractable symbol. Setting aside the Peluse-Prendiville step for now, the first obstacle is that the natural approximation to the symbol does not have sufficiently accurate error bounds if a Siegel zero exists. While one could in principle fix this by adding a Siegel correction term to the approximation, we found it simpler to use the arguments of Teräväinen to essentially replace the von Mangoldt weight by a “Cramér approximant” 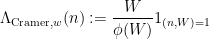
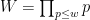 and
and  is a parameter (we make the quasipolynomial choice
is a parameter (we make the quasipolynomial choice 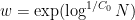 for a suitable absolute constant
for a suitable absolute constant  ). This approximant is then used for most of the argument, with relatively routine changes; for instance, an
). This approximant is then used for most of the argument, with relatively routine changes; for instance, an  improving estimate needs to be replaced by a weighted analogue that is relatively easy to establish from the unweighted version due to an
improving estimate needs to be replaced by a weighted analogue that is relatively easy to establish from the unweighted version due to an  smoothing effect, and a sharp
smoothing effect, and a sharp  -adic bilinear averaging estimate for large can also be adapted to handle a suitable -adic weight by a minor variant of the arguments. The most tricky step is to obtain a weighted version of the Peluse-Prendiville inverse theorem. Here we encounter the technical problem that the Cramér approximant, despite having many good properties (in particular, it is non-negative and has well-controlled correlations thanks to the fundamental lemma of sieve theory), is not of “Type I”, which turns out to be quite handy when establishing inverse theorems. So for this portion of the argument, we switch from the Cramér approximant to the Heath-Brown approximant
-adic bilinear averaging estimate for large can also be adapted to handle a suitable -adic weight by a minor variant of the arguments. The most tricky step is to obtain a weighted version of the Peluse-Prendiville inverse theorem. Here we encounter the technical problem that the Cramér approximant, despite having many good properties (in particular, it is non-negative and has well-controlled correlations thanks to the fundamental lemma of sieve theory), is not of “Type I”, which turns out to be quite handy when establishing inverse theorems. So for this portion of the argument, we switch from the Cramér approximant to the Heath-Brown approximant 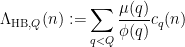
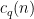 is the Ramanujan sum
is the Ramanujan sum  ,
, 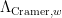 , and
, and 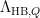 in various Gowers uniformity-type norms, which allows us to switch relatively easily between the different weights in practice; hopefully these comparison theorems will be useful in other applications as well.
in various Gowers uniformity-type norms, which allows us to switch relatively easily between the different weights in practice; hopefully these comparison theorems will be useful in other applications as well.