A pilot project in universal algebra to explore new ways to collaborate and use machine assistance?
What's new 2024-09-26
Traditionally, mathematics research projects are conducted by a small number (typically one to five) of expert mathematicians, each of which are familiar enough with all aspects of the project that they can verify each other’s contributions. It has been challenging to organize mathematical projects at larger scales, and particularly those that involve contributions from the general public, due to the need to verify all of the contributions; a single error in one component of a mathematical argument could invalidate the entire project. Furthermore, the sophistication of a typical math project is such that it would not be realistic to expect a member of the public, with say an undergraduate level of mathematics education, to contribute in a meaningful way to many such projects.
For related reasons, it is also challenging to incorporate assistance from modern AI tools into a research project, as these tools can “hallucinate” plausible-looking, but nonsensical arguments, which therefore need additional verification before they could be added into the project.
Proof assistant languages, such as Lean, provide a potential way to overcome these obstacles, and allow for large-scale collaborations involving professional mathematicians, the broader public, and/or AI tools to all contribute to a complex project, provided that it can be broken up in a modular fashion into smaller pieces that can be attacked without necessarily understanding all aspects of the project as a whole. Projects to formalize an existing mathematical result (such as the formalization of the recent proof of the PFR conjecture of Marton, discussed in this previous blog post) are currently the main examples of such large-scale collaborations that are enabled via proof assistants. At present, these formalizations are mostly crowdsourced by human contributors (which include both professional mathematicians and interested members of the general public), but there are also some nascent efforts to incorporate more automated tools (either “good old-fashioned” automated theorem provers, or more modern AI-based tools) to assist with the (still quite tedious) task of formalization.
However, I believe that this sort of paradigm can also be used to explore new mathematics, as opposed to formalizing existing mathematics. The online collaborative “Polymath” projects that several people including myself organized in the past are one example of this; but as they did not incorporate proof assistants into the workflow, the contributions had to be managed and verified by the human moderators of the project, which was quite a time-consuming responsibility, and one which limited the ability to scale these projects up further. But I am hoping that the addition of proof assistants will remove this bottleneck.
I am particularly interested in the possibility of using these modern tools to explore a class of many mathematical problems at once, as opposed to the current approach of focusing on only one or two problems at a time. This seems like an inherently modularizable and repetitive task, which could particularly benefit from both crowdsourcing and automated tools, if given the right platform to rigorously coordinate all the contributions; and it is a type of mathematics that previous methods usually could not scale up to (except perhaps over a period of many years, as individual papers slowly explore the class one data point at a time until a reasonable intuition about the class is attained). Among other things, having a large data set of problems to work on could be helpful for benchmarking various automated tools and compare the efficacy of different workflows.
One recent example of such a project was the Busy Beaver Challenge, which showed this July that the fifth Busy Beaver number 

More specifically I would like to propose the following (admittedly artificial) project as a pilot to further test out this paradigm, which was inspired by a MathOverflow question from last year, and discussed somewhat further on my Mastodon account shortly afterwards.
The problem is in the field of universal algebra, and concerns the (medium-scale) exploration of simple equational theories for magmas. A magma is nothing more than a set 




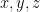 are indeterminate variables in the magma . On the other hand the (left) identity axiom
are indeterminate variables in the magma . On the other hand the (left) identity axiom  would not be considered an equational axiom here, as it involves a constant
would not be considered an equational axiom here, as it involves a constant  (the identity element), which we will not consider here.
(the identity element), which we will not consider here.To illustrate the project I have in mind, let me first introduce eleven examples of equational axioms for magmas:
- Equation1:
- Equation2:
- Equation3:
- Equation4:
- Equation5:
- Equation6:
- Equation7:
- Equation8:
- Equation9:
- Equation10:
- Equation11:









 to have at most one element; at the opposite extreme, the reflexive axiom Equation11 is the weakest, being satisfied by every single magma.
to have at most one element; at the opposite extreme, the reflexive axiom Equation11 is the weakest, being satisfied by every single magma.One can then ask which axioms imply which others. For instance, Equation1 implies all the other axioms in this list, which in turn imply Equation11. Equation8 implies Equation9 as a special case, which in turn implies Equation10 as a special case. The full poset of implications can be depicted by the following Hasse diagram:

This in particular answers the MathOverflow question of whether there were equational axioms intermediate between the constant axiom Equation1 and the associative axiom Equation10.
Most of the implications here are quite easy to prove, but there is one non-trivial one, obtained in this answer to a MathOverflow post closely related to the preceding one:
Proposition 1 Equation4 implies Equation7.
Proof: Suppose that

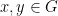 . Specializing to
. Specializing to  , we conclude
, we conclude 
 is idempotent:
is idempotent: 
 by in (1) and then using (2), we see that
by in (1) and then using (2), we see that  commutes with
commutes with  :
: 

 , which is Equation7.
, which is Equation7. 
A formalization of the above argument in Lean can be found here.
I will remark that the general question of determining whether one set of equational axioms determines another is undecidable; see Theorem 14 of this paper of Perkins. (This is similar in spirit to the more well known undecidability of various word problems.) So, the situation here is somewhat similar to the Busy Beaver Challenge, in that past a certain point of complexity, we would necessarily encounter unsolvable problems; but hopefully there would be interesting problems and phenomena to discover before we reach that threshold.
The above Hasse diagram does not just assert implications between the listed equational axioms; it also asserts non-implications between the axioms. For instance, as seen in the diagram, the commutative axiom Equation7 does not imply the Equation4 axiom

 with the addition operation
with the addition operation  . More generally, the diagram asserts the following non-implications, which (together with the indicated implications) completely describes the poset of implications between the eleven axioms:
. More generally, the diagram asserts the following non-implications, which (together with the indicated implications) completely describes the poset of implications between the eleven axioms: - Equation2 does not imply Equation3.
- Equation3 does not imply Equation5.
- Equation3 does not imply Equation7.
- Equation5 does not imply Equation6.
- Equation5 does not imply Equation7.
- Equation6 does not imply Equation7.
- Equation6 does not imply Equation10.
- Equation7 does not imply Equation6.
- Equation7 does not imply Equation10.
- Equation9 does not imply Equation8.
- Equation10 does not imply Equation9.
- Equation10 does not imply Equation6.
As one can see, it is already somewhat tedious to compute the Hasse diagram of just eleven equations. The project I propose is to try to expand this Hasse diagram by a couple orders of magnitude, covering a significantly larger set of equations. The set I propose is the set 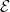




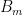


 equations come in pairs by the symmetry of equality, so the total size of is
equations come in pairs by the symmetry of equality, so the total size of is 
It is not clear to me at all what the geometry of
A brute force computation of the poset 

I would imagine that there is some “low-hanging fruit” that could establish a large number of implications (or anti-implications) quite easily. For instance, laws such as Equation2 or Equation3 more or less completely describe the binary operation 

Perhaps, in analogy with formalization projects, we could have a semi-formal “blueprint” evolving in parallel with the formal Lean component of the project. This way, the project could accept human-written proofs by contributors who do not necessarily have any proficiency in Lean, as well as contributions from automated tools (such as the aforementioned Prover9 and Mace4), whose output is in some other format than Lean. The task of converting these semi-formal proofs into Lean could then be done by other humans or automated tools; in particular I imagine modern AI tools could be particularly valuable for this portion of the workflow. I am not quite sure though if existing blueprint software can scale to handle the large number of individual proofs that would be generated by this project; and as this portion would not be formally verified, a significant amount of human moderation might also be needed here, and this also might not scale properly. Perhaps the semi-formal portion of the project could instead be coordinated on a forum such as this blog, in a similar spirit to past Polymath projects.
It would be nice to be able to integrate such a project with some sort of graph visualization software that can take an incomplete determination of the poset 
Anyway, I would be happy to receive any feedback on this project; in addition to the previous requests, I would be interested in any suggestions for improving the project, as well as gauging whether there is sufficient interest in participating to actually launch it. (I am imagining running it vaguely along the lines of a Polymath project, though perhaps not formally labeled as such.)