Higher uniformity of arithmetic functions in short intervals II. Almost all intervals
What's new 2024-11-11
Kaisa Matomäki, Maksym Radziwill, Fernando Xuancheng Shao, Joni Teräväinen, and myself have (finally) uploaded to the arXiv our paper “Higher uniformity of arithmetic functions in short intervals II. Almost all intervals“. This is a sequel to our previous paper from 2022. In that paper, discorrelation estimates such as
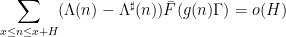
 is the von Mangoldt function,
is the von Mangoldt function, 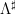 was some suitable approximant to that function,
was some suitable approximant to that function, 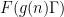 was a nilsequence, and
was a nilsequence, and ![{[x,x+H]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Cx%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) was a reasonably short interval in the sense that
was a reasonably short interval in the sense that  for some
for some 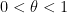 and some small
and some small  . In that paper, we were able to obtain non-trivial estimates for
. In that paper, we were able to obtain non-trivial estimates for  as small as
as small as 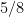 , and for some other functions such as divisor functions
, and for some other functions such as divisor functions 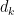 for small values of
for small values of  , we could lower somewhat to values such as
, we could lower somewhat to values such as  ,
, 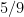 ,
,  of . This had a number of analytic number theory consequences, for instance in obtaining asymptotics for additive patterns in primes in such intervals. However, there were multiple obstructions to lowering much further. Even for the model problem when
of . This had a number of analytic number theory consequences, for instance in obtaining asymptotics for additive patterns in primes in such intervals. However, there were multiple obstructions to lowering much further. Even for the model problem when 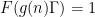 , that is to say the study of primes in short intervals, until recently the best value of available was
, that is to say the study of primes in short intervals, until recently the best value of available was 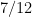 , although this was very recently improved to
, although this was very recently improved to  by Guth and Maynard.
by Guth and Maynard.However, the situation is better when one is willing to consider estimates that are valid for almost all intervals, rather than all intervals, so that one now studies local higher order uniformity estimates of the form
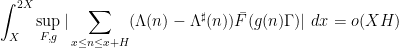
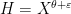 and the supremum is over all nilsequences of a certain Lipschitz constant on a fixed nilmanifold
and the supremum is over all nilsequences of a certain Lipschitz constant on a fixed nilmanifold 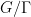 . This generalizes local Fourier uniformity estimates of the form
. This generalizes local Fourier uniformity estimates of the form 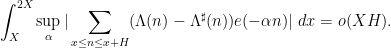
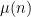 (where, as per the Möbius pseudorandomness conjecture, the approximant
(where, as per the Möbius pseudorandomness conjecture, the approximant 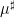 should be taken to be zero, at least in the absence of a Siegel zero). This is because if one could get estimates of this form for any
should be taken to be zero, at least in the absence of a Siegel zero). This is because if one could get estimates of this form for any  that grows sufficiently slowly in
that grows sufficiently slowly in  (in particular
(in particular 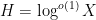 ), this would imply the (logarithmically averaged) Chowla conjecture, as I showed in a previous paper.
), this would imply the (logarithmically averaged) Chowla conjecture, as I showed in a previous paper.While one can lower 


- For the von Mangoldt function, we can get
in the error terms; for divisor functions, one can even get power savings in this regime.
- For the Möbius function, we can get
, recovering our previous result with Tamar Ziegler, but now with
- We can now also get comparable results for the divisor function.
As sample applications, we can obtain Hardy-Littlewood conjecture asymptotics for arithmetic progressions of almost all given steps 

Our proofs are rather long, but broadly follow the “contagion” strategy of Walsh, generalized from the Fourier setting to the higher order setting. Firstly, by standard Heath–Brown type decompositions, and previous results, it suffices to control “Type II” discorrelations such as
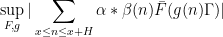
 , and some suitable functions
, and some suitable functions 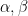 supported on medium scales. So the bad case is when for most , one has a discorrelation
supported on medium scales. So the bad case is when for most , one has a discorrelation 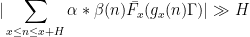
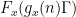 that depends on .
that depends on .The main issue is the dependency of the polynomial 

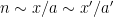 (and I am being extremely vague as to what the relation “
(and I am being extremely vague as to what the relation “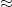 ” means here). By a higher order (and quantitatively stronger) version of Walsh’s contagion analysis (which is ultimately to do with separation properties of Farey sequences), we can show that this implies that these polynomials
” means here). By a higher order (and quantitatively stronger) version of Walsh’s contagion analysis (which is ultimately to do with separation properties of Farey sequences), we can show that this implies that these polynomials 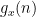 (which exert influence over intervals ) can “infect” longer intervals
(which exert influence over intervals ) can “infect” longer intervals ![{[x', x'+Ha]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%27%2C+x%27%2BHa%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) with some new polynomials
with some new polynomials 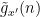 and various
and various 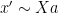 , which are related to many of the previous polynomials by a relationship that looks very roughly like
, which are related to many of the previous polynomials by a relationship that looks very roughly like 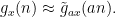
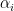 and some primes
and some primes 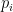 with
with 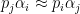 for all
for all  , then one should have
, then one should have 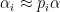 for some
for some  , where I am being vague here about what means (and why it might be useful to have primes). By iterating this sort of contagion relationship, one can eventually get the to behave like an Archimedean character
, where I am being vague here about what means (and why it might be useful to have primes). By iterating this sort of contagion relationship, one can eventually get the to behave like an Archimedean character 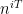 for some
for some  that is not too large (polynomial size in ), and then one can use relatively standard (but technically a bit lengthy) “major arc” techiques based on various integral estimates for zeta and
that is not too large (polynomial size in ), and then one can use relatively standard (but technically a bit lengthy) “major arc” techiques based on various integral estimates for zeta and  functions to conclude.
functions to conclude.