Bounding sums or integrals of non-negative quantities
What's new 2023-10-01
A common task in analysis is to obtain bounds on sums


 is some simple region (such as an interval) in one or more dimensions, and
is some simple region (such as an interval) in one or more dimensions, and  is an explicit (and elementary) non-negative expression involving one or more variables (such as
is an explicit (and elementary) non-negative expression involving one or more variables (such as  or
or  , and possibly also some additional parameters. Often, one would be content with an order of magnitude upper bound such as
, and possibly also some additional parameters. Often, one would be content with an order of magnitude upper bound such as 

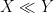 (or
(or 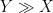 or
or 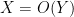 ) to denote the bound
) to denote the bound 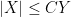 for some constant
for some constant  ; sometimes one wishes to also obtain the matching lower bound, thus obtaining
; sometimes one wishes to also obtain the matching lower bound, thus obtaining 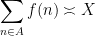
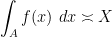
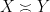 is synonymous with
is synonymous with 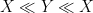 . Finally, one may wish to obtain a more precise bound, such as
. Finally, one may wish to obtain a more precise bound, such as 
 is a quantity that goes to zero as the parameters of the problem go to infinity (or some other limit). (For a deeper dive into asymptotic notation in general, see this previous blog post.)
is a quantity that goes to zero as the parameters of the problem go to infinity (or some other limit). (For a deeper dive into asymptotic notation in general, see this previous blog post.)Here are some typical examples of such estimation problems, drawn from recent questions on MathOverflow:
- (i) (From this question) If
and
, is the expression
finite? - (ii) (From this question) If
, how can one show that
- (iii) (From this question) Can one show that
asfor an explicit constant
, and what is this constant?
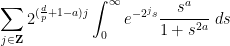
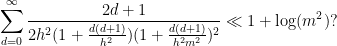
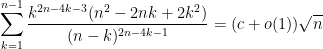
Compared to other estimation tasks, such as that of controlling oscillatory integrals, exponential sums, singular integrals, or expressions involving one or more unknown functions (that are only known to lie in some function spaces, such as an 
Somewhat in the spirit of this previous post on analysis problem solving strategies, I am going to try here to collect some general principles and techniques that I have found useful for these sorts of problems. As with the previous post, I hope this will be something of a living document, and encourage others to add their own tips or suggestions in the comments.
— 1. Asymptotic arithmetic —
Asymptotic notation is designed so that many of the usual rules of algebra and inequality manipulation continue to hold, with the caveat that one has to be careful if subtraction or division is involved. For instance, if one knows that 







 to be non-negative. As a rule of thumb, if your calculations have arrived at a situation where a signed or oscillating sum or integral appears inside the big-O notation, or on the right-hand side of an estimate, without being “protected” by absolute value signs, then you have probably made a serious error in your calculations.)
to be non-negative. As a rule of thumb, if your calculations have arrived at a situation where a signed or oscillating sum or integral appears inside the big-O notation, or on the right-hand side of an estimate, without being “protected” by absolute value signs, then you have probably made a serious error in your calculations.)Another rule of inequalities that is inherited by asymptotic notation is that if one has two bounds
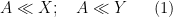 , then one can combine them into the unified asymptotic bound
, then one can combine them into the unified asymptotic bound 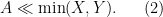
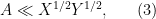 and
and  in order to simplify the minimum. So in practice, when trying to establish an estimate, one often starts with using conservative bounds such as (2) in order to maximize one’s chances of getting any proof (no matter how messy) of the desired estimate, and only after such a proof is found, one tries to look for more elegant approaches using less efficient bounds such as (3).
in order to simplify the minimum. So in practice, when trying to establish an estimate, one often starts with using conservative bounds such as (2) in order to maximize one’s chances of getting any proof (no matter how messy) of the desired estimate, and only after such a proof is found, one tries to look for more elegant approaches using less efficient bounds such as (3).For instance, suppose one wanted to show that the sum
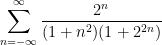
 by
by  or by
or by  , one obtains the bounds
, one obtains the bounds 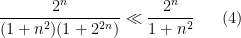
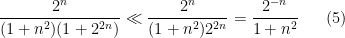

 , where
, where  dominates, and
dominates, and 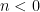 , where
, where  dominates. In the former case we see (from the ratio test, for instance) that the sum
dominates. In the former case we see (from the ratio test, for instance) that the sum 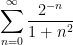


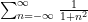 . This is a less “efficient” estimate, because one has conceded a lot of the decay in the summand by using (6) (the summand used to be exponentially decaying in , but is now only polynomially decaying), but it is still sufficient for the purpose of establishing absolute convergence.
. This is a less “efficient” estimate, because one has conceded a lot of the decay in the summand by using (6) (the summand used to be exponentially decaying in , but is now only polynomially decaying), but it is still sufficient for the purpose of establishing absolute convergence.One of the key advantages of dealing with order of magnitude estimates, as opposed to sharp inequalities, is that the arithmetic becomes tropical. More explicitly, we have the important rule
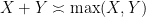 are non-negative, since we clearly have
are non-negative, since we clearly have 
 , then
, then 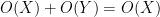 . That is to say, given two orders of magnitudes, any term
. That is to say, given two orders of magnitudes, any term 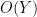 of equal or lower order to a “main term”
of equal or lower order to a “main term” 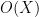 can be discarded. This is a very useful rule to keep in mind when trying to estimate sums or integrals, as it allows one to discard many terms that are not contributing to the final answer. It also sets up the fundamental divide and conquer strategy for estimation: if one wants to prove a bound such as , it will suffice to obtain a decomposition
can be discarded. This is a very useful rule to keep in mind when trying to estimate sums or integrals, as it allows one to discard many terms that are not contributing to the final answer. It also sets up the fundamental divide and conquer strategy for estimation: if one wants to prove a bound such as , it will suffice to obtain a decomposition 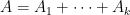
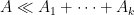 by some bounded number of components
by some bounded number of components  , and establish the bounds
, and establish the bounds 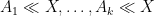 separately. Typically the will be (morally at least) smaller than the original quantity – for instance, if is a sum of non-negative quantities, each of the
separately. Typically the will be (morally at least) smaller than the original quantity – for instance, if is a sum of non-negative quantities, each of the 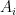 might be a subsum of those same quantities – which means that such a decomposition is a “free move”, in the sense that it does not risk making the problem harder. (This is because, if the original bound is to be true, each of the new objectives must also be true, and so the decomposition can only make the problem logically easier, not harder.) The only costs to such decomposition are that your proofs might be
might be a subsum of those same quantities – which means that such a decomposition is a “free move”, in the sense that it does not risk making the problem harder. (This is because, if the original bound is to be true, each of the new objectives must also be true, and so the decomposition can only make the problem logically easier, not harder.) The only costs to such decomposition are that your proofs might be  times longer, as you may be repeating the same arguments times, and that the implied constants in the bounds may be worse than the implied constant in the original bound. However, in many cases these costs are well worth the benefits of being able to simplify the problem into smaller pieces. As mentioned above, once one successfully executes a divide and conquer strategy, one can go back and try to reduce the number of decompositions, for instance by unifying components that are treated by similar methods, or by replacing strong but unwieldy estimates with weaker, but more convenient estimates.
times longer, as you may be repeating the same arguments times, and that the implied constants in the bounds may be worse than the implied constant in the original bound. However, in many cases these costs are well worth the benefits of being able to simplify the problem into smaller pieces. As mentioned above, once one successfully executes a divide and conquer strategy, one can go back and try to reduce the number of decompositions, for instance by unifying components that are treated by similar methods, or by replacing strong but unwieldy estimates with weaker, but more convenient estimates.The above divide and conquer strategy does not directly apply when one is decomposing into an unbounded number of pieces 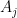


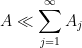

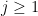 and some constant
and some constant  , since this would imply
, since this would imply  ; a -dependent bound such as
; a -dependent bound such as  would be useless for this application, as then the growth of the implied constant in could overwhelm the exponential decay in the
would be useless for this application, as then the growth of the implied constant in could overwhelm the exponential decay in the  factor). Exponential decay is in fact overkill; polynomial decay such as
factor). Exponential decay is in fact overkill; polynomial decay such as 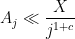

 diverges logarithmically), although in many such situations one could try to still salvage the bound by working a lot harder to squeeze some additional logarithmic factors out of one’s estimates. For instance, if one can improve \eqre{ajx} to
diverges logarithmically), although in many such situations one could try to still salvage the bound by working a lot harder to squeeze some additional logarithmic factors out of one’s estimates. For instance, if one can improve \eqre{ajx} to 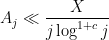
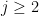 and some constant , since (by the integral test) the sum
and some constant , since (by the integral test) the sum 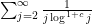 converges (and one can treat the
converges (and one can treat the 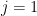 term separately if one already has (8)).
term separately if one already has (8)).Sometimes, when trying to prove an estimate such as
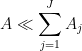
 is finite but unbounded) but is unsure of how to proceed next. Often the next thing to do is to study the extreme terms
is finite but unbounded) but is unsure of how to proceed next. Often the next thing to do is to study the extreme terms  and
and 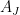 of this decomposition, and first try to establish (the presumably simpler) tasks of showing that
of this decomposition, and first try to establish (the presumably simpler) tasks of showing that  and
and 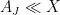 . Often once one does so, it becomes clear how to combine the treatments of the two extreme cases to also treat the intermediate cases, obtaining a bound
. Often once one does so, it becomes clear how to combine the treatments of the two extreme cases to also treat the intermediate cases, obtaining a bound 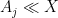 for each individual term, leading to the inferior bound
for each individual term, leading to the inferior bound 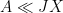 ; this can then be used as a starting point to hunt for additional gains, such as the exponential or polynomial gains mentioned previously, that could be used to remove this loss of . (There are more advanced techniques, such as those based on controlling moments such as the square function
; this can then be used as a starting point to hunt for additional gains, such as the exponential or polynomial gains mentioned previously, that could be used to remove this loss of . (There are more advanced techniques, such as those based on controlling moments such as the square function  , or trying to understand the precise circumstances in which a “large values” scenario
, or trying to understand the precise circumstances in which a “large values” scenario  occurs, and how these scenarios interact with each other for different , but these are beyond the scope of this post, as they are rarely needed when dealing with sums or integrals of elementary functions.)
occurs, and how these scenarios interact with each other for different , but these are beyond the scope of this post, as they are rarely needed when dealing with sums or integrals of elementary functions.)— 1.1. Psychological distinctions between exact and asymptotic arithmetic —
The adoption of the “divide and conquer” strategy requires a certain mental shift from the “simplify, simplify” strategy that one is taught in high school algebra. In the latter strategy, one tries to collect terms in an expression make them as short as possible, for instance by working with a common denominator, with the idea that unified and elegant-looking expressions are “simpler” than sprawling expressions with many terms. In contrast, the divide and conquer strategy is intentionally extremely willing to greatly increase the total length of the expressions to be estimated, so long as each individual component of the expressions appears easier to estimate than the original one. Both strategies are still trying to reduce the original problem to a simpler problem (or collection of simpler sub-problems), but the metric by which one judges whether the problem has become simpler is rather different.
A related mental shift that one needs to adopt in analysis is to move away from the exact identities that are so prized in algebra (and in undergraduate calculus), as the precision they offer is often unnecessary and distracting for the task at hand, and often fail to generalize to more complicated contexts in which exact identities are no longer available. As a simple example, consider the task of estimating the expression
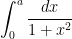
 is a parameter. With a trigonometric substitution, one can evaluate this expression exactly as
is a parameter. With a trigonometric substitution, one can evaluate this expression exactly as  , however the presence of the arctangent can be inconvenient if one has to do further estimation tasks (for instance, if
, however the presence of the arctangent can be inconvenient if one has to do further estimation tasks (for instance, if  depends in a complicated fashion on other parameters, which one then also wants to sum or integrate over). Instead, by observing the trivial bounds
depends in a complicated fashion on other parameters, which one then also wants to sum or integrate over). Instead, by observing the trivial bounds 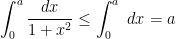

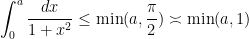
 , is often good enough for many applications (par ticularly in situations where one is willing to concede constants in the bounds), and can be more tractible to work with than the exact answer. Furthermore, these arguments can be adapted without difficulty to treat similar expressions such as
, is often good enough for many applications (par ticularly in situations where one is willing to concede constants in the bounds), and can be more tractible to work with than the exact answer. Furthermore, these arguments can be adapted without difficulty to treat similar expressions such as 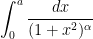
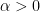 , which need not have closed form exact expressions in terms of elementary functions such as the arctangent when
, which need not have closed form exact expressions in terms of elementary functions such as the arctangent when  is non-integer.
is non-integer.As a general rule, instead of relying exclusively on exact formulae, one should seek approximations that are valid up to the degree of precision that one seeks in the final estimate. For instance, suppose one one wishes to establish the bound
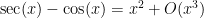 . If one was clinging to the exact identity mindset, one could try to look for some trigonometric identity to simplify the left-hand side exactly, but the quicker (and more robust) way to proceed is just to use Taylor expansion up to the specified accuracy
. If one was clinging to the exact identity mindset, one could try to look for some trigonometric identity to simplify the left-hand side exactly, but the quicker (and more robust) way to proceed is just to use Taylor expansion up to the specified accuracy 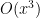 to obtain
to obtain 
 to obtain
to obtain 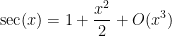
 directly, but as this is a series that is usually not memorized, this can take a little bit more time than just computing it directly to the required accuracy.) Note that the notion of “specified accuracy” may have to be interpreted in a relative sense if one is planning to multiply or divide several estimates together. For instance, if one wishes to establsh the bound
directly, but as this is a series that is usually not memorized, this can take a little bit more time than just computing it directly to the required accuracy.) Note that the notion of “specified accuracy” may have to be interpreted in a relative sense if one is planning to multiply or divide several estimates together. For instance, if one wishes to establsh the bound  , one needs an approximation
, one needs an approximation  , but one only needs an approximation
, but one only needs an approximation 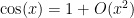
 , because the cosine is to be multiplied by
, because the cosine is to be multiplied by  . Here the key is to obtain estimates that have a relative error of , compared to the main term (which is for cosine, and for sine).
. Here the key is to obtain estimates that have a relative error of , compared to the main term (which is for cosine, and for sine).The following table lists some common approximations that can be used to simplify expressions when one is only interested in order of magnitude bounds (with
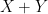

 or
or 
 ,
,  ,
, 
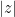



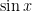
 real
real 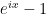
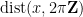 real
real 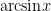
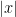
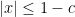

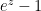 ,
, 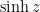 ,
, 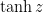

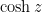
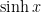 ,
, 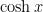
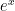


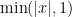 real
real 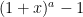

 ,
, 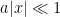





 ,
, 
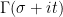

 ,
, 
On the other hand, some exact formulae are still very useful, particularly if the end result of that formula is clean and tractable to work with (as opposed to involving somewhat exotic functions such as the arctangent). The geometric series formula, for instance, is an extremely handy exact formula, so much so that it is often desirable to control summands by a geometric series purely to use this formula (we already saw an example of this in (7)). Exact integral identities, such as
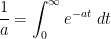

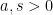 (where
(where  is the Gamma function) are also quite commonly used, and fundamental exact integration rules such as the change of variables formula, the Fubini-Tonelli theorem or integration by parts are all esssential tools for an analyst trying to prove estimates. Because of this, it is often desirable to estimate a sum by an integral. The integral test is a classic example of this principle in action: a more quantitative versions of this test is the bound
is the Gamma function) are also quite commonly used, and fundamental exact integration rules such as the change of variables formula, the Fubini-Tonelli theorem or integration by parts are all esssential tools for an analyst trying to prove estimates. Because of this, it is often desirable to estimate a sum by an integral. The integral test is a classic example of this principle in action: a more quantitative versions of this test is the bound 
 are integers and
are integers and ![{f: [a-1,b+1] \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bf%3A+%5Ba-1%2Cb%2B1%5D+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is monotone decreasing, or the closely related bound
is monotone decreasing, or the closely related bound 
 are reals and
are reals and ![{f: [a,b] \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bf%3A+%5Ba%2Cb%5D+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is monotone (either increasing or decreasing); see Lemma 2 of this previous post. Such bounds allow one to switch back and forth quite easily between sums and integrals as long as the summand or integrand behaves in a mostly monotone fashion (for instance, if it is monotone increasing on one portion of the domain and monotone decreasing on the other). For more precision, one could turn to more advanced relationships between sums and integrals, such as the Euler-Maclaurin formula or the Poisson summation formula, but these are beyond the scope of this post.
is monotone (either increasing or decreasing); see Lemma 2 of this previous post. Such bounds allow one to switch back and forth quite easily between sums and integrals as long as the summand or integrand behaves in a mostly monotone fashion (for instance, if it is monotone increasing on one portion of the domain and monotone decreasing on the other). For more precision, one could turn to more advanced relationships between sums and integrals, such as the Euler-Maclaurin formula or the Poisson summation formula, but these are beyond the scope of this post.Exercise 1 Supposeobeys the quasi-monotonicity property
whenever
. Show that
for any integers
.
Exercise 2 Use (11) to obtain the “cheap Stirling approximation”for any natural number
. (Hint: take logarithms to convert the product
into a sum.)
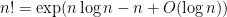
With practice, you will be able to identify any term in a computation which is already “negligible” or “acceptable” in the sense that its contribution is always going to lead to an error that is smaller than the desired accuracy of the final estimate. One can then work “modulo” these negligible terms and discard them as soon as they appear. This can help remove a lot of clutter in one’s arguments. For instance, if one wishes to establish an asymptotic of the form
 and lower order error , any component of that one can already identify to be of size is negligible and can be removed from “for free”. Conversely, it can be useful to add negligible terms to an expression, if it makes the expression easier to work with. For instance, suppose one wants to estimate the expression
and lower order error , any component of that one can already identify to be of size is negligible and can be removed from “for free”. Conversely, it can be useful to add negligible terms to an expression, if it makes the expression easier to work with. For instance, suppose one wants to estimate the expression 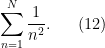

 to the expression (12) to rewrite it as
to the expression (12) to rewrite it as 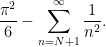
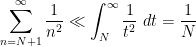
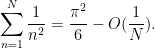
Another psychological shift when switching from algebraic simplification problems to estimation problems is that one has to be prepared to let go of constraints in an expression that complicate the analysis. Suppose for instance we now wish to estimate the variant
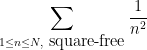 to be square-free. An identity from analytic number theory (the Euler product identity) lets us calculate the exact sum
to be square-free. An identity from analytic number theory (the Euler product identity) lets us calculate the exact sum 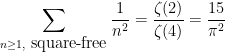


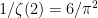 , in fact) of all integers are square-free. Now that this constraint has been removed, we can use the integral test as before and obtain the reasonably accurate asymptotic
, in fact) of all integers are square-free. Now that this constraint has been removed, we can use the integral test as before and obtain the reasonably accurate asymptotic 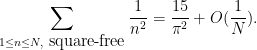
— 2. More on decomposition —
The way in which one decomposes a sum or integral such as 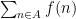





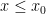
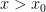
If an expression involves a distance 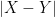








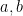 , which we will take to be distinct for sake of this discussion. This particular integral is simple enough that it can be evaluated exactly (for instance using contour integration techniques), but in the spirit of Principle 1, let us avoid doing so and instead try to decompose this expression into simpler pieces. A graph of the integrand reveals that it peaks when is near or near
, which we will take to be distinct for sake of this discussion. This particular integral is simple enough that it can be evaluated exactly (for instance using contour integration techniques), but in the spirit of Principle 1, let us avoid doing so and instead try to decompose this expression into simpler pieces. A graph of the integrand reveals that it peaks when is near or near  . Inspired by this, one can decompose the region of integration into three pieces:
. Inspired by this, one can decompose the region of integration into three pieces:- (i) The region where
.
- (ii) The region where
.
- (iii) The region where
.
(This is not the only way to cut up the integral, but it will suffice. Often there is no “canonical” or “elegant” way to perform the decomposition; one should just try to find a decomposition that is convenient for the problem at hand.)
The reason why we want to perform such a decomposition is that in each of the three cases, one can simplify how the integrand depends on 
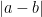


 are now comparable to each other, and so the contribution of this region is comparable to
are now comparable to each other, and so the contribution of this region is comparable to 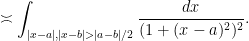
 , we will discard the
, we will discard the 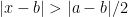 constraint, upper bounding this integral by
constraint, upper bounding this integral by 
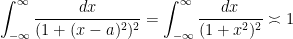

 . Putting all this together, and dividing into the cases
. Putting all this together, and dividing into the cases 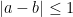 and
and 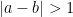 , one can soon obtain a total bound of
, one can soon obtain a total bound of 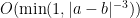 for the entire integral. One can also adapt this argument to show that this bound is sharp up to constants, thus
for the entire integral. One can also adapt this argument to show that this bound is sharp up to constants, thus 
A powerful and common type of decomposition is dyadic decomposition. If the summand or integrand involves some quantity 
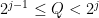


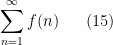
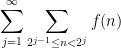
 separately (hoping to get some exponential or polynomial decay in ). The classical technique of Cauchy condensation is a basic example of this strategy. But one can also dyadically decompose other quantities than . For instance one can perform a “vertical” dyadic decomposition (in contrast to the “horizontal” one just performed) by rewriting (15) as
separately (hoping to get some exponential or polynomial decay in ). The classical technique of Cauchy condensation is a basic example of this strategy. But one can also dyadically decompose other quantities than . For instance one can perform a “vertical” dyadic decomposition (in contrast to the “horizontal” one just performed) by rewriting (15) as 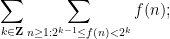
 is
is 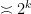 , we may simplify this to
, we may simplify this to 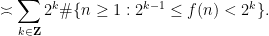
 for various . In a similar spirit, we have
for various . In a similar spirit, we have 
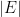 denotes the Lebesgue measure of a set
denotes the Lebesgue measure of a set  , and now we are faced with a geometric problem of estimating the measure of some explicit set. This allows one to use geometric intuition to solve the problem, instead of multivariable calculus:
, and now we are faced with a geometric problem of estimating the measure of some explicit set. This allows one to use geometric intuition to solve the problem, instead of multivariable calculus:Exercise 3 Letbe a smooth compact submanifold of
. Establish the bound
for all
, where the implied constants are allowed to depend on
. (This can be accomplished either by a vertical dyadic decomposition, or a dyadic decomposition of the quantity
.)

Exercise 4 Solve problem (ii) from the introduction to this post by dyadically decomposing in thevariable.
Remark 5 By such tools as (10), (11), or Exercise 1, one could convert the dyadic sums one obtains from dyadic decomposition into integral variants. However, if one wished, one could “cut out the middle-man” and work with continuous dyadic decompositions rather than discrete ones. Indeed, from the integral identityfor any
, together with the Fubini–Tonelli theorem, we obtain the continuous dyadic decomposition
for any quantity
that is positive whenever
parameter which would be tricky to execute if this were a discrete variable.
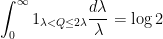

— 3. Exponential weights —
Many sums involve expressions that are “exponentially large” or “exponentially small” in some parameter. A basic rule of thumb is that any quantity that is “exponentially small” will likely give a negligible contribution when compared against quantities that are not exponentially small. For instance, if an expression involves a term of the form 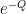
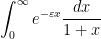
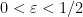 , this heuristic suggests that the dominant contribution should come from the region
, this heuristic suggests that the dominant contribution should come from the region 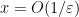 , in which one can bound
, in which one can bound  simply by and obtain an upper bound of
simply by and obtain an upper bound of 
To make such a heuristic precise, one can perform a dyadic decomposition in the exponential weight 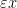
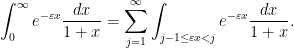
Exercise 6 Use this decomposition to rigorously establish the boundfor any

Exercise 7 Solve problem (i) from the introduction to this post.
More generally, if one is working with a sum or integral such as
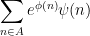

 and a lower order amplitude
and a lower order amplitude  , then one typically expects the dominant contribution to come from the region where
, then one typically expects the dominant contribution to come from the region where  comes close to attaining its maximal value. If this maximum is attained on the boundary, then one typically has geometric series behavior away from the boundary, and one can often get a good estimate by obtaining geometric series type behavior. For instance, suppose one wants to estimate the error function
comes close to attaining its maximal value. If this maximum is attained on the boundary, then one typically has geometric series behavior away from the boundary, and one can often get a good estimate by obtaining geometric series type behavior. For instance, suppose one wants to estimate the error function 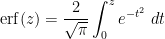
 . In view of the complete integral
. In view of the complete integral 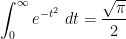
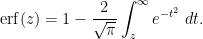
 attains its maximum at the left endpoint
attains its maximum at the left endpoint  and decays quickly away from that endpoint. One could estimate this by dyadic decomposition of as discussed previously, but a slicker way to proceed here is to use the convexity of
and decays quickly away from that endpoint. One could estimate this by dyadic decomposition of as discussed previously, but a slicker way to proceed here is to use the convexity of 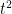 to obtain a geometric series upper bound
to obtain a geometric series upper bound 
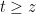 , which on integration gives
, which on integration gives 
 .
.Exercise 8 In the converse direction, establish the upper boundfor some absolute constant
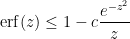
Exercise 9 Iffor some
, show that
(Hint: estimate the ratio between consecutive binomial coefficients
and then control the sum by a geometric series).

When the maximum of the exponent
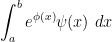 attains a non-degenerate global maximum at some interior point
attains a non-degenerate global maximum at some interior point 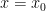 . The rule of thumb here is that
. The rule of thumb here is that 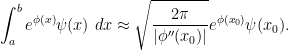 is close to . Here we can perform a Taylor expansion
is close to . Here we can perform a Taylor expansion 
 and
and  . Also, if is continuous, then
. Also, if is continuous, then 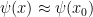 when is close to . Thus we should be able to estimate the above integral by the gaussian integral
when is close to . Thus we should be able to estimate the above integral by the gaussian integral 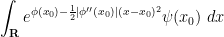
 as desired.
as desired.Let us illustrate how this argument can be made rigorous by considering the task of estimating the factorial
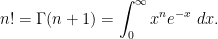 is large, we will consider
is large, we will consider 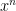 to be part of the exponential weight rather than the amplitude, writing this expression as
to be part of the exponential weight rather than the amplitude, writing this expression as 
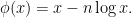 attains a global maximum at
attains a global maximum at  , with
, with  and
and  . We will therefore decompose this integral into three pieces
. We will therefore decompose this integral into three pieces 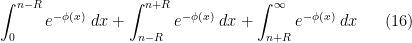
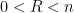 is a radius parameter which we will choose later, as it is not immediately obvious for now how to select it.
is a radius parameter which we will choose later, as it is not immediately obvious for now how to select it.The main term is expected to be the middle term, so we shall use crude methods to bound the other two terms. For the first part where 

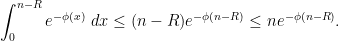
 to be much smaller than , so there is not much point to saving the tiny
to be much smaller than , so there is not much point to saving the tiny 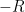 term in the
term in the 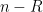 factor.) For the third part where
factor.) For the third part where  , is decreasing, but bounding
, is decreasing, but bounding 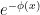 by
by 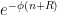 would not work because of the unbounded nature of ; some additional decay is needed. Fortunately, we have a strict increase
would not work because of the unbounded nature of ; some additional decay is needed. Fortunately, we have a strict increase 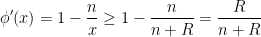 , so by the intermediate value theorem we have
, so by the intermediate value theorem we have 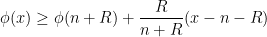

 , then we will have
, then we will have  in the region
in the region 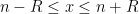 , so by Taylor’s theorem with remainder
, so by Taylor’s theorem with remainder 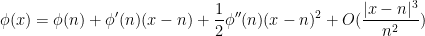

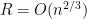 , then the error term is bounded and we can exponentiate to obtain
, then the error term is bounded and we can exponentiate to obtain 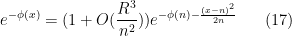 and hence
and hence 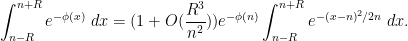
 , we can use the error function type estimates from before to estimate
, we can use the error function type estimates from before to estimate 
Exercise 10 Solve problem (iii) from the introduction. (Hint: extract out the termto write as the exponential factor
, placing all the other terms (which are of polynomial size) in the amplitude function
. The function
; perform a Taylor expansion and mimic the arguments above.)