On a conjecture of Marton
What's new 2023-11-14
Tim Gowers, Ben Green, Freddie Manners, and I have just uploaded to the arXiv our paper “On a conjecture of Marton“. This paper establishes a version of the notorious Polynomial Freiman–Ruzsa conjecture (first proposed by Katalin Marton):
Theorem 1 (Polynomial Freiman–Ruzsa conjecture) Letbe such that
. Then
can be covered by at most
translates of a subspace
of
of cardinality at most
The previous best known result towards this conjecture was by Konyagin (as communicated in this paper of Sanders), who obtained a similar result but with 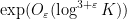

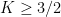



The exponent 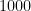
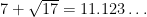
In this paper we will focus exclusively on the characteristic 
Much of the prior progress on this sort of result has proceeded via Fourier analysis. Perhaps surprisingly, our approach uses no Fourier analysis whatsoever, being conducted instead entirely in “physical space”. Broadly speaking, it follows a natural strategy, which is to induct on the doubling constant 

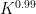
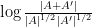

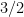
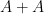
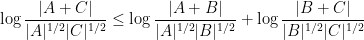 to means that the various Ruzsa distances that need to be summed are controlled by a convergent geometric series).
to means that the various Ruzsa distances that need to be summed are controlled by a convergent geometric series).There are a number of possible ways to try to “improve” a set
- (i) Replacing
) of a large subspace
- (ii) Replacing
for a “typical”
. For instance, if
Unfortunately, there are sets 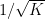
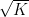
This begins to suggest a potential strategy: show that at least one of the operations (i) or (ii) will improve the doubling constant, or at least not worsen it too much; and in the latter case, perform some more complicated operation to locate the desired doubling constant improvement.
A sign that this strategy might have a chance of working is provided by the following heuristic argument. If 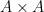
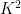
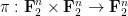

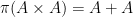

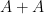

Unfortunately, this argument does not seem to be easily made rigorous using the traditional doubling constant; even just showing the significantly weaker statement that 


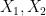

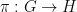
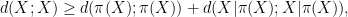
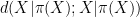 is defined as
is defined as 
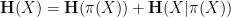

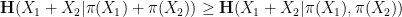
Applying this inequality with 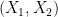


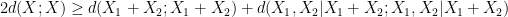
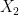 is determined by
is determined by 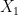 once one fixes
once one fixes 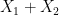 )
) 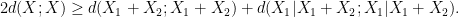
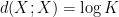 , then at least one of
, then at least one of 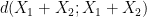 or
or 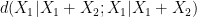 will be less than or equal to
will be less than or equal to 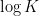 . This is the entropy analogue of at least one of (i) or (ii) improving, or at least not degrading the doubling constant, although there are some minor technicalities involving how one deals with the conditioning to in the second term that we will gloss over here (one can pigeonhole the instances of to different events
. This is the entropy analogue of at least one of (i) or (ii) improving, or at least not degrading the doubling constant, although there are some minor technicalities involving how one deals with the conditioning to in the second term that we will gloss over here (one can pigeonhole the instances of to different events 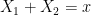 ,
, 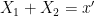 , and “depolarise” the induction hypothesis to deal with distances
, and “depolarise” the induction hypothesis to deal with distances 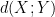 between pairs of random variables
between pairs of random variables  that do not necessarily have the same distribution). Furthermore, we can even calculate the defect in the above inequality: a careful inspection of the above argument eventually reveals that
that do not necessarily have the same distribution). Furthermore, we can even calculate the defect in the above inequality: a careful inspection of the above argument eventually reveals that 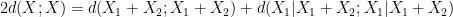
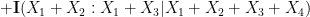
 . This leads (modulo some technicalities) to the following interesting conclusion: if neither (i) nor (ii) leads to an improvement in the entropic doubling constant, then and
. This leads (modulo some technicalities) to the following interesting conclusion: if neither (i) nor (ii) leads to an improvement in the entropic doubling constant, then and  are conditionally independent relative to
are conditionally independent relative to  . This situation (or an approximation to this situation) is what we refer to in the paper as the “endgame”.
. This situation (or an approximation to this situation) is what we refer to in the paper as the “endgame”.A version of this endgame conclusion is in fact valid in any characteristic. But in characteristic
 , and using symmetry we now conclude that if we are in the endgame exactly (so that the mutual information is zero), then the independent sum of two copies of
, and using symmetry we now conclude that if we are in the endgame exactly (so that the mutual information is zero), then the independent sum of two copies of 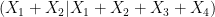 has exactly the same distribution; in particular, the entropic doubling constant here is zero, which is certainly a reduction in the doubling constant.
has exactly the same distribution; in particular, the entropic doubling constant here is zero, which is certainly a reduction in the doubling constant.To deal with the situation where the conditional mutual information is small but not completely zero, we have to use an entropic version of the Balog-Szemeredi-Gowers lemma, but fortunately this was already worked out in an old paper of mine (although in order to optimise the final constant, we ended up using a slight variant of that lemma).
I am planning to formalize this paper in the Lean4 language. Further discussion of this project will take place on this Zulip stream, and the project itself will be held at this Github repository.