The (local) unit of intelligence is FLOPs
Windows On Theory 2023-06-05
[Crossposting again on Lesswrong and Windowsontheory, with the hope I am not overstaying my welcome in LW.]
Wealth can be measured by dollars. This is not a perfect measurement: it’s hard to account for purchasing power and circumstances when comparing people across varying countries or time periods. However, within a particular place and time, one can measure wealth in the local currency. It still does not capture everything (e.g., future earnings, social connections). But generally, all else being roughly equal, the more dollars one has, the wealthier one is.
How do we measure intelligence? I am not interested in measuring the intelligence of individual humans or individual animals. Nor am I looking for a universal absolute scale of intelligence on which we could rank humans, elephants, and GPT4. (Indeed, it doesn’t seem that a one-dimensional comparison can be made; for example, we seem to be more intelligent than elephants on most dimensions, but they do have an impressive memory.) Rather, I want to compare different species within the same genus or different models within the same general architecture (e.g., Transformers).
I think it’s fair to say that the local unit of intelligence for animal species is neurons. While elephants have larger brains than humans, within the genus Homo, to a first approximation, the bigger the brain, the more intelligent the species.
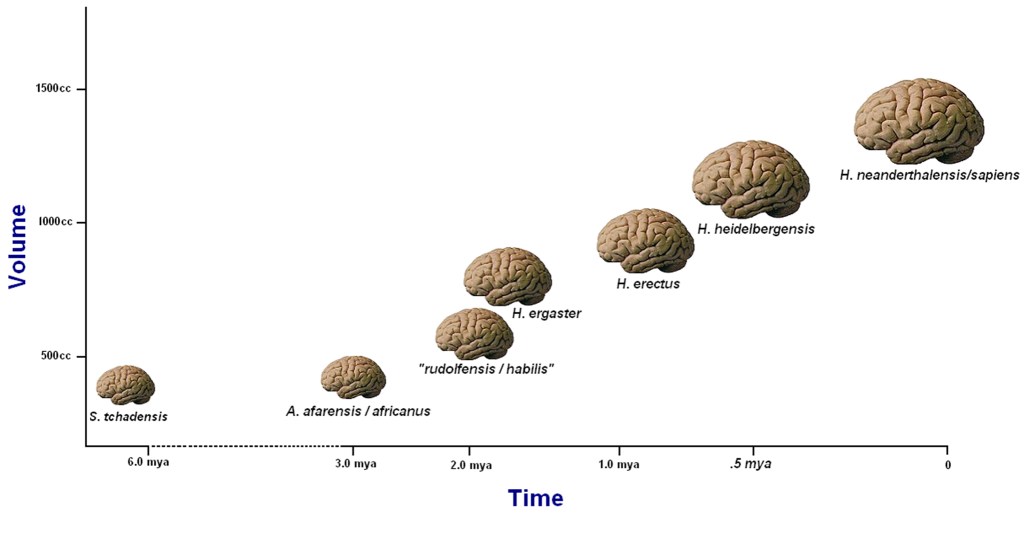
(Figure from Bolihus et al.)
I claim that within the current architectures and training frameworks of large language models, the local unit of intelligence is FLOPs. That is, as long as we follow the current paradigm of training transformer-based architectures within best practices of scaling compute and data, the more compute resources (FLOPs) invested in training the model, the more intelligent it is. This is an imperfect measurement, but probably one that is better than trying to give models “IQ exams” that were designed for humans (and even there have dubious value). Another way to say this is that the intelligence of the model scales with the number of “load-bearing gradient steps” that have gone into training it.
So far, it might seem like a tautology, but as I claimed in the “intelligence forklift” post, this does have some implications. In particular, current general-purpose models such as ChatGPT are built in two phases. The first phase is a pretraining phase, in which the model is trained in a Trillion or more gradient steps on the next-token prediction task. The second phase is the adaptation/fine-tuning phase, in which, whether through instruction-tuning, reinforcement learning on human feedback (RLHF) or other methods, the model is “fine tuned” using fewer than a million gradient steps to be a better instruction-following or chatting agent. In other words, more than 99.9% (maybe as much as 99.9999%) of the FLOPs / gradient steps in training the model are invested during its pretraining phase. (One reason that the fine-tuning phase involves much fewer gradient steps is that, while the first phase can use any static data grabbed from the Internet, the second phase requires data that was especially collected for this task and often needs human labeling as well.)
The adaptation phase can make a huge difference in the usefulness of the model. The chatbot arena doesn’t even contain non-fine-tuned models, and we can see that smaller but well-tuned models can put up a decent fight against ones that have at least 10 times the parameters (and so roughly at least 100 times the training compute). Unlike sashimi, language models should not be consumed raw.

However, their “intelligence” is ultimately derived from the FLOPs invested in the base models. (See also this paper on the limitations of fine-tuning to close capability gaps.) Fine-tuning, whether using RL or not, is the proverbial “cherry on the cake” and the pre-trained model captures more than 99.9% of the intelligence of the model. That pretrained model is not an agent and does not have goals though it can “play one on TV” in the sense of coming up with plans and proposed actions if prompted to do so. (In LW language, a simulator.) This is why a pretrained model can be modeled as an “intelligence forklift”. Just like a forklift supplies strength but is useless without someone driving it, so does the pretrained model supply intelligence, but that intelligence needs to be directed via fine-tuning, conditioning on prompts, etc. Another way to think of the pre-trained model is as the bee colony and the adapter as the queen. (That is, if the queen bee was actually telling bees what to do rather than just laying eggs.)
In that sense, while I agree with Gwern that agentic models are more useful and that “we don’t want low log-loss error on ImageNet, we want to refind a particular personal photo” , I disagree that “Agent AIs [will be] more intelligent than Tool AIs.” Intelligence and usefulness are not the same thing.
Implications for alignment
If the pre-trained model does not have goals, then there is no sense in “aligning” it. Rather, there is a separation of concerns, with a highly intelligent but goal-less pre-trained model (“forklift”) and a not-so-intelligent but goal-directed adaptor (“driver”). It is the latter one that we need to align:
The component of an AI system that needs to be aligned is not the component that accounts for its intelligence.
That is a hopeful lesson since the adaptor can be a much smaller (e.g. have drastically fewer parameters) and tractable object. However, it does not mean that the alignment problem is easy and that we are insulated from the complexities of the pretrained model:
A forklift with a speed of 1000mph might not be actively trying to kill you, but this could still be the end result.
In particular, we don’t understand the biases the pre-trained model inherits from the data, nor the way that these may play out when we use the model in applications. However, it does seem that for a pretrained model to be as good at its job as possible, it should learn all the biases in its data but not be constrained to any of them. It should be able to adapt to any context real or imagined and be the “perfect actor” that can take on any character’s personality.
The traditional “anthropomorphic” view of intelligence is as something that “belongs” to an individual or agent and that this agent has some sort of preferences or goals (a.k.a a utility function). Hence a potential future super-intelligent AI was thought of as an “alien” that pursues some goals. Under this viewpoint, we want to either “box” the alien to control its impact or “align” its goals to ours. Both of these options treat the AI system as a single component encompassing both goals and intelligence. However, if goals and intelligence parts correspond to different components, we may be able to “take the alien’s brain for a ride” and build a variety of systems that share the same capabilities but have very different objectives and profiles.
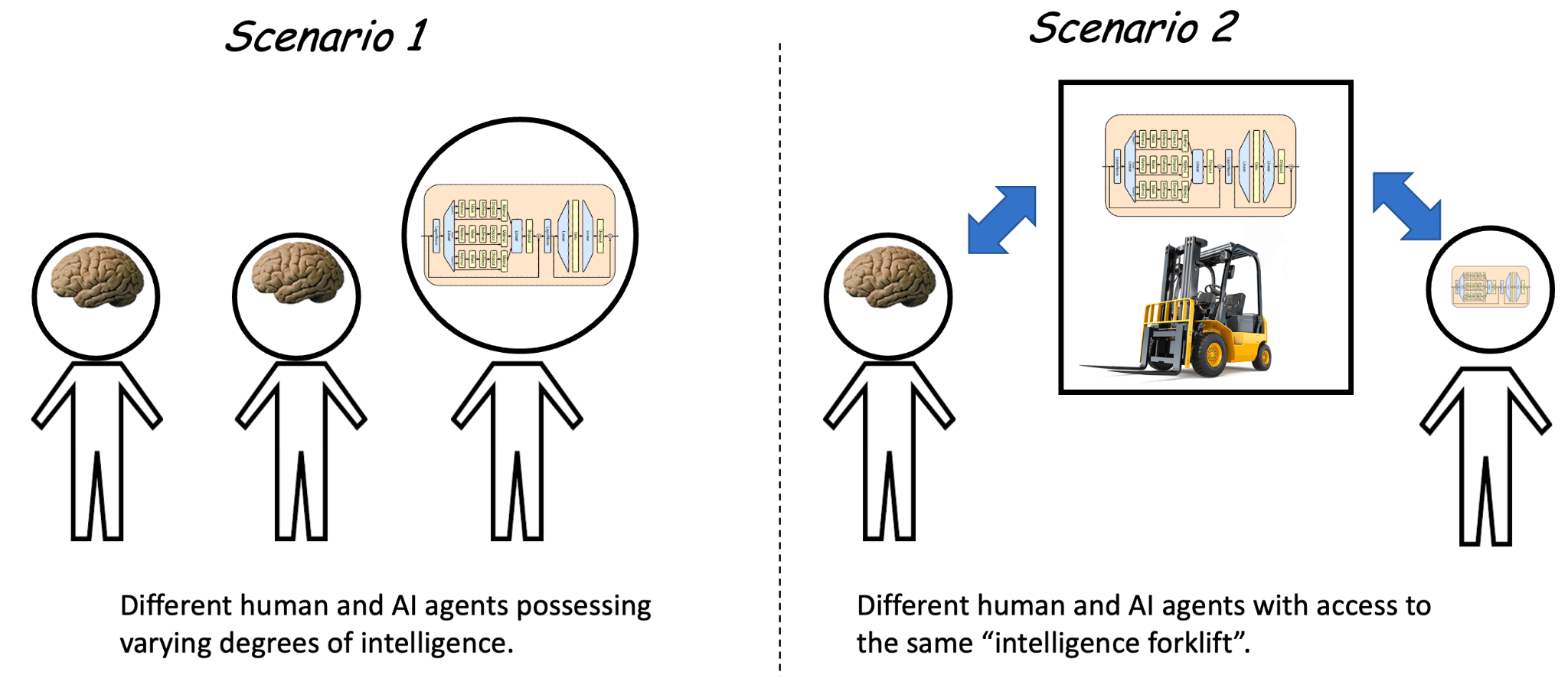
To be clear, the “intelligence forklift” view does not preclude building an “anti-aligned” agent on top of a pre-trained model that is malicious, dishonest, and harmful. It just means that such an agent would not have an automatic intelligence advantage over other agents (including humans) since all of them can have access to a shared “intelligence engine” provided by the goal-less pretrained models. This is what I illustrated as “scenario 2” in this figure (taken from my previous post):
What about “self play”?
The above assumes that the intelligence component of a model is obtained by executing gradient steps on static data, but what if this data is itself generated by the model? This is what happened with games such as Go and Chess. Originally models were trained by predicting the next move of human games scraped from the Internet, but to improve beyond the quality of these data, models needed to play against themselves and generate new games. They could then filter out only the most successful ones and hence generate data that is of higher quality than the original games they trained on. (Eventually, it turned out that with this approach you don’t need to start with any data for games such as Chess and Go, hence the “Zero” in AlphaZero.)
Self-play makes a lot of sense in games where there is a very clear notion of winning and losing, but what would be the analog for language models? I don’t know the answer to this in general, but in the realm of scientific literature, there is an analogous process. The model could play the roles of authors and reviewers alike, generate new papers, subject them to peer review, revise and resubmit, etc. At least in fields that don’t require “wet labs”, this could lead to the model simulating the scientific literature of 2024, then 2025, and so on and so forth. Models that manage to do this would be amazing and would speed up scientific progress tremendously. However, I believe they could still be (just more powerful) “intelligence forklifts”. Model outputs influencing its inputs can lead to a “positive feedback loop,” and so this is not certain. But I do not see an inherent reason why models could not be arbitrarily intelligent and still completely without goals. In the words of Scott Alexander, no matter how intelligent they are, models could still be “enlightened” and realize that
“once you stop obsessing over the character you’re playing, you notice the GIANT SUPER-ACCURATE WORLD MODEL TAKING UP 99.99% OF YOUR BRAIN.”