Sampling from the tail end of the normal distribution
Wildon's Weblog 2025-02-04
The purpose of this post is to present two small observations on the normal distribution, with more speculative applications to academic recruitment. The mathematical part at least is rigorous.
Tails of the normal distribution and the exponential approximation
We can sample from the tail end of the standard normal distribution 


Please pause for a moment and ask yourself: do you expect the variance of the tail-end sample to increase with
The answer, less intuitively I think, is that the variance decreases as 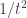

Thus, the larger 
Alternatively, and I like that this can be done entirely in one’s head, observe that for large 

and so the normal distribution conditioned on 


The University of Erewhon
In the selection process for the University of Erewhon, applicants are invited sit a fiendishly difficult exam. The mean score is zero (these candidates are of course rejected) and the faculty recruits the tiny minority who exceed the pass mark. The result, of course, is that the faculty recruits not the best mathematicians, but those best at passing their absurd test. (Nonetheless there is a long queue at the examination centre each year: people want jobs!) But more deleteriously, the effect is to create a monoculture: modelling exam-taking ability as an
I have gone through selection processes in my life that had something in common with this obvious parody (sometimes unjustly benefitting, other times, in retrospect, being glad to fail), and believe I can write from experience that the result has never been good. The alternative of course is to use multiple criteria when recruiting, allowing that some successful candidates may be weak in some areas, while very strong in others. Rather obvious, I know, but I think it’s interesting that a very simple mathematical argument backs up this conclusion.
In the next part of the post we’ll see that the effect of luck can mean that Erewhonian-style recruitment not only creates a mono-culture, it doesn’t even successfully select the most talented candidates.
The effect of luck
If our intuition about tail events is perhaps suspect, our intuition for conditional probability is surely worse. When the two come together, by conditioning on rare events, the effects can be catastrophic. Selection bias is frequently overlooked even by those who should know better. It seems quite possible to me that we’re here today only because in the many worlds in which the delicate balance of nuclear deterrence failed, there is no-one left in the charred embers to read blog posts on selection bias. Or to pick a less extreme example, would you spend £1000 to attend a seminar given by a panel of lottery winners in which they promise to reveal the detail of their gambling strategies?
Returning to the normal distribution, and the University of Erewhon, suppose that with probability 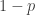





I think here most people would intuitively guess the right answer, but the magnitude of the effect is striking. The table below shows the number of ‘average’ and ‘lucky’ people when we take a million samples according to the scheme above, keeping only the samples that are at least 
averageluckyratio1127064615730.481.553375317740.60218361130700.712.5492445620.933105411761.123.51872501.34424512.13Thus even though average people outnumber lucky people four to one, when we sample from the 