Daniel Kahneman, 1934–2024
Gödel’s Lost Letter and P=NP 2024-04-05
With some connections to my chess research
 Modified from source
Modified from sourceDaniel Kahneman passed away last week. He won the 2002 Nobel Prize in Economics, shared with Vernon Smith, and was awarded a Presidential Medal of Freedom in 2013.
Today I review some of his work on human decision making and how my chess niche may reflect it.
Kahneman is best introduced by two popular books: his own Thinking, Fast and Slow in 2011 and The Undoing Project by Michael Lewis in 2016. Both books pay copious homage to his longtime research partner Amos Tversky, whom we mentioned with reference to chess here and the “hot hand” phenomenon in basketball and chess.
Other than there, we have not previously mentioned his work. It is all about human decision making and its dependence on features that are overlooked by a strictly numerically rational calculus of expected value. Prominent examples include:
- Whether the value is guaranteed or probabilistic;
- Whether the expected value involves possibility of loss;
- How the value—even if guaranteed—relates to other values currently at issue;
- Whether a choice is harmonious with recent preoccupations;
- Whether the sun shone through clouds on the way in to work or play.
These factors represent Kahneman’s work with Tversky and others on (1) prospect theory, including (2) loss aversion, then (3) framing, and (4) priming. Item (5) comes from his latest work and 2021 book Noise: A Flaw in Human Judgment with Olivier Sibony and Cass Sunstein. In controlled experiments where objective criteria were held the same, Kahneman and co-workers found more extreme variation in outcomes than the human judges regarded a-priori as consistent with their expertise and institutional values.
Levels of Replication
Kahneman combated noise at a different level in social economics and psychology studies. In a 2012 open letter he called for greater attention to replicating studies, and in 2014 he proposed structures for doing so. This accompanied and presaged his growing awareness that several studies (by others) that he highlighted in his 2011 book, especially on priming, were on shaky ground.
Prospect theory has been replicated to various degrees. So has framing. But Jay Livingston of Montclair State University raised a fundamental criticism of these and myriad other behavioral studies in a 2016 post. He first quotes Robert Frank in evident allusion to a famous Kahneman-Tversky paper on framing:
It is common … for someone to be willing to drive across town to save $10 on a $20 clock radio, but unwilling to do so to save $10 on a $1,000 television set.
How do we tell “common”? The quantitative answers all come from studies that pose hypothetical questions of the form, “In this situation … what would you choose?” There are no studies that tracked 100 people who actually had the opportunity to save $10 on a radio in a competing store across town, and 100 others who could save a (paltry) $10 on a big flat-screen TV by walking out of Best Buy and going to Target. Livingston continues:
It’s surprising that social scientists who cite this study take the “would do” response at face value, surprising because another well-known topic in behavioral economics is the discrepancy between what people say they will do and what they actually do. People say that they will start exercising regularly, or save more of their income, or start that diet on Monday. Then Monday comes, and everyone else at the table is having dessert, and well, you know how it is.
The visceral reactions to “what would you do?” type questions I’ve tried seem convincing enough for real life. But I agree that real-life data would give a higher level of replication. We maybe should hope that being able to automatically track store visits and sales discussions and subsequent car movements remains a pipe dream. So how can we possibly gather real-life data?
Enter Chess
The possibility I pose is:
Can we glean evidence for Kahneman’s phenomena from copious data in real-life competitive chess?
For a first example, here is the chess analogue of the framing example ascribed by Livingston. The data come from several thousand games by players rated near 2200 on the Elo rating scale. The x-axis is the advantage or disadvantage for the player to move, measured by the strong chess program Stockfish 7 in the common units of pawns ahead or behind. The y-axis is the average difference in position value (AD) after the player’s move. The regressions are weighted by the number of positions in each value “bucket”; there are hundreds per value for entries near 0.00.

When the position is dead even, the average move is an error of almost exactly 
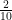
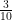
Now a pawn advantage or deficit—as judged by an unseen chess program—is quite a normal condition for playing human chess. It is not a cause for overconfidence or playing safe when ahead, nor panic or desperation when behind. The conclusion I draw is that the magnitude of advantage sets a context of value. A small edge of 0.2 pawns is like having $20 at stake, while 2 pawns is like $200. The effect shows across the spectrum of skill levels. Here are diagrams for amateur players rated near 1400 and grandmasters rated near 2600. The absolute values differ but the linearity is much the same:

The effect may stem from the greater variability of the chess program’s values in positions where one side has substantial advantage. It may be lower when the player to move is 

Human players perceive differences in value in proportion to the net value in the position, not absolutely.
Is this relation to the net position value really an instance of Kahneman-Tversky’s “framing”? The answer would require further work and argument. Regardless, correcting for this effect is a vital tuning step for my model, with noise-reduction benefits beyond the overt differences I showed in this old post.
Priming and Noise
I will address (4) and (5) on the above list then tackle (1) and (2). For (4) priming, the basic point is how having a multi-turn plan in mind governs move choice in positions after the one that set the plan in motion. A famous instance is the double blunder in the 2014 world championship match between Magnus Carlsen and Viswanathan Anand. Ignoring an innocuous pair of moves that left the position unchanged, Anand made three consecutive moves with his rightmost pawn. The second move of that pawn missed a way to punish Carlsen’s misstep on the other side of the board.
The simplest point is that move choices in consecutive turns of a game are not independent. It is however a sparse nearest-neighbor dependence, and I’ve been able to quantify it as an effective reduction of the sample size of moves and corresponding adjustment of the z-scores computed by my model, using the process described here. Thus we can point to chess decisions depending on recently past actions—but whether that equates to dependence on past attitudes and perceptions as in the “priming” theory is more nebulous.
The extent to which chess decisions are noisy is a wide-open question. The analogy to the judging situations in the Noise book seems apt: chess has well-defined rules and strategic goals and most positions have unique best moves of normative essence. Here are some planks for my model’s relevance:
- The model’s probability projections for all moves in all positions are internally accurate via metrics developed here and exhibited recently here.
- Just for the computer’s best moves, the projections exactly match actual human frequencies of finding them—and those frequencies are no higher than 60% for the world’s best players, down under 40% for beginners.
Thus one can conclude indirectly that noise in chess is considerable. A direct test would involve the distribution of move choices in the same position by multiple players. Positions that occur in multiple games generally arise only in the opening stages and in endgames with only a handful of pieces on the board. The former is an imperfect test because players memorize opening lines (called “book”) and ways to play those lines often follow fashion. Endgame positions would make a better test because the normative best moves are usually clear. Two cases of Carlsen erring in simple-looking positions are here and toward the end here.
Prospect Theory in Chess?
An article a year-plus ago by Junta Ikeda, an International Master from Australia who plays and blogs on the Lichess playing site under the name “datajunkie,” includes prospect theory as #4 of five lessons of Kahneman’s book for chess players. At #5 is regret theory, which can be related to loss aversion.
The relevant aspects of prospect theory he mentions are overestimating chances in an objectively losing position and playing too cautiously when well ahead. The problem in trying to test them is that unlike Kahneman’s choice-and-betting situations, there is no simple and definite “chance of winning” or expectation benchmark to compare to. The chance-of-winning curves I discussed here are derived from human chess games to begin with, and are based on pawns-ahead calculations by chess programs that do not translate to chance-of-winning for individual positions.
Can predictions of prospect theory be formulated for chess and tested on large data, nevertheless? I see one predicate related to loss aversion that is readily tested, though it relies internally on the prediction accuracy of my model for its key concept, which was formulated by Tamal Biswas in his research discussed here:
Definition 1 Consider a chess position of value
for the player
to move. A move
is a good gamble if:
- the move
. However,
- the expected value
after the opponent’s move, using their projected probabilities in the model, gives
.
More simply put, a good gamble is a move that can be refuted, but whose refutation is hard for the opponent to find. It is really “a gamble” if you see or know in advance that a refutation exists—or have a hunch of the same—rather than merely overlook it. In testing the following question, however, we would only detect the existence of a refutation, whether foreseen or not.
Do chess players make good gambles in practice? Or do they find safer moves that fail to maximize their winning prospects?
The latter would be Kahneman’s prediction. The dependence on the skill rating of the players involved would add an extra dimension: are stronger players observed to play safer? This needs to account that the probability of the opponent finding the refutation likewise scales up with the opponent’s skill rating.
Open Problems
What are the prospects for chess as a testbed for many more of Kahneman’s ideas than the mentions of chess in his book?
 Data Junkie source
Data Junkie source[added tag for Tversky; added note on regression weighting in third section]