Should These Quantities Be Linear?
Gödel’s Lost Letter and P=NP 2023-08-04
Drastic proposals for revamping the chess rating system

Jeff Sonas is a statistician who runs a consulting firm. He also studies skill at chess. He has advised the International Chess Federation (FIDE) about the Elo rating system for over a quarter century. He and FIDE have just released a 19-page study and proposal for a massive overhaul of the system.
Today I ask whether larger scientific contexts support the proposal. Besides this, I advocate even more radical measures.
Arpad Elo’s system was adopted by the US Chess Federation in 1960 and by FIDE in 1970. A notable recent endorsement comes from Nate Silver and continued use by FiveThirtyEight for sports predictions.
Sonas’s ChessMetrics project extends Elo ratings backward for historical chess greats before 1970. My Intrinsic Pereformance Ratings (IPRs) are mostly substantially lower than his ratings over the time before 1940. For example, he gives the American great Paul Morphy and the first world champion Wilhelm Steinitz ratings well over 2700, in line with today’s champions, over sets of games whose IPRs are under 2500. We are, however, measuring different quantities. Sonas evaluates the relationship to contemporary players as Elo would. I measure the quality of their move choices according to today’s strongest computer programs. Today’s players avail more chess knowledge than their predecessors and need more preparation of opening stages with computer analysis just to stay in place.
Sonas’s work meshes with FIDE’s system after 1970. From there on, our systems have agreed closely through the 2010s. What has happened since then, before and during the pandemic, is our point of departure.
The Puzzle
Sonas offers an explanation for a puzzle I expressed here in February 2019. In my 2011 stem paper with the late Guy Haworth, we observed a linear relationship between Elo rating and two quantities judged by strong programs, called “engines” 
- The percentage of playing the move judged best and listed first by
- The accumulated difference in value between played moves judged inferior by
Owing to paucity of games by players under Elo 2000 whose moves are preserved in databases, Haworth and I went down only to 1600. The range 1600 to 2700 still showed a strong linear fit for T1 and ASD in 2019. But when extended down to the lowest FIDE rating 1000 and up to 2800 with many more games recently played at that level too, nonlinearity became clear:

The rating is the x-axis; T1-match is on y. Sonas’s prescription rectifies this curve in the bluntest way imaginable:
Ratings under 2000 have become distended—largely because of policy changes after the year 2010—so that the interval
needs to be summarily mapped onto
.
The effect on the figure, compressing the left half of the x-axis to the right, would make a linear relationship again (pace data above 2700 amid its greater uncertainties). Indeed, if I project my data from 2000 to 2800+ (a range left unscathed by Sonas) using a weighted linear regression from this applet, I get a line that shifts by close to 400 at the bottom left:

Important to note, this is before the pandemic froze and discombobulated the entire rating system. How Sonas treats the pandemic is one of two major issues I see needing to be threshed out before going forward. But let’s first see his main evidence, which is completely apart from the above.
Sonas’s Evidence
The rating system is based around a sigmoid curve that projects a percentage score for a player 



Here is his table of the actual-versus-predicted margin for the years 2008 until 2012. At the end of 2012, the minimum FIDE rating was extended downward from 1200 to 1000 where it stands today.

Note that all shortfalls over 3% have one or both players under 2000. These cases also dominate the raw number of games played (though not of games whose moves are preserved in databases); Sonas notes that 85% of listed players are rated under 2000. Sonas also gives a chart for games played in 2021–2023 with far greater shortfalls up to 15%, but we will address that next. The main support for his proposed “Compression” of sub-2000 ratings, plus further fixes for handling new and novice players, is that their use in 2017–2019 would have eliminated almost all the discrepancies:


Indeed, the remaining discrepancy is commensurate with the shortfall in Mark Glickman’s analysis incorporating rating uncertainty as a parameter. I covered how that shortfall is an unavoidable “Law” in this 2018 post.
Whether actions that would have worked so well in 2017 remain well-tuned for the rating system coming out of the pandemic needs further examination.
Pandemic Lag, Again
This past weekend brought a premier—and public—example of an issue I began quantifying in September 2020 and highlighted in a big post two years ago:

Here and in Tarjei Svensen’s story for Chess.com and several other places, I have replied with reference to my article “Pandemic Lag” on this blog two years ago. The point is:
Velpula Sarayu’s 1845 rating was woefully out of date from the lack of officially rated in-person chess (in India) during the pandemic, while her chess brain improved in other ways. A truer estimate of her current strength is 2398 given by my formula in that mid-2021 article (slightly updated). This vast difference should not only dispel some visible whispers of suspicion but also obviate most of the surprise.
One might argue 2398 is too high for her, but over entire fields of similar open tournaments my formula continues to be accurate. Those tournaments have plenty of young players. At Pontevedra, 56 players out of 79 had at least one game preserved on auto-recording boards; 24 of those were born in 2000 or later. My formula adjusts 23 including Ms. Sarayu upwards; one other’s July 2023 rating has caught up and overtopped my formula’s estimate, which is based on the April 2020 rating and 39 months passing since then. From two other major July Opens, ones I officially monitored, I have the entire set of games:
- Astana Zhuldyzdary A: 108 players, 63 adjusted upwards, 3 others (including Hans Niemann) topped adjustments; average lag adjustment +229; average rating for whole field after adjustments 2341; average IPR 2347. Difference = 6.
- Biel Masters (MTO): 98 players, 54 adjusted upwards, 5 others topped the formula; average lag adjustment +242; average rating after adjustments 2408; average IPR 2383. Difference = -25.
In most previous large tournaments (that preserved all their game records) as well:
My estimates are not only globally vastly more accurate than the official ratings, they are closer by an order of magnitude compared to the adjustments themselves.
Thus, I have been maintaining a rough but much more accurate rendition of the FIDE rating system, all by myself, for almost three years. This has been in actuality, not a simulation. The consistency has surprised me coming from a back-of-the-envelope formula. There is yet no comprehensive study of the growth curves of young players, a lack that was exposed by arguments over the Niemann case last year. The measurements I drew on in autumn 2020 were fairly close to the formula’s rounding. The Astana and Biel examples are the freshest data.
My Recommendations
My first recommendation follows forthwith, insofar as the Sonas paper presents results from the years 2021–2023 and the post-pandemic rating system is the one we need to fix, not the system as of 2019.
The charts and simulations in the Sonas paper for the years 2021–2023 should be redone using my estimated ratings.
There are two caveats. The second leads into problems in the realm above Elo 2000 that are already widely sensed by players but left out of Sonas’s prescriptions. The first is that my estimates fix more than the “pandemic lag” problem per se. They also fix in one shot the “natural lag” of catching up with the current strength of a rapidly improving (young) player by rating past tournaments. Insofar as natural lag is addressed by other means, it may need to be separated out of my adjustments so that the redone simulations do not overcorrect.
The second point is simple—I can reference the above example to convey it:
Each of Ms. Sarayu’s master-level opponents lost about 5 rating points just for sitting down to play her with her rating saying “1845.” This is regardless of whether they won, lost, or drew the game—they come out lower than what they would have from a fair estimate of her playing strength.
Face a dozen such kids—note they are more than half the players—and you are staring down a loss of 50 or more rating points, even after some rating bounceback. The result has been deflation of older players whose ratings were largely stable before the pandemic. This is touched on by Sonas but will be harder to address. I have been busy trying to quantify this deflation for a particularly well-defined and well-sized set of players: grandmaster and master-level female players, who have played among themselves in a headline series of tournaments. Identifying and correcting this deflation is my second recommendation, but it will be harder to implement.
My third recommendation is that the analysis and simulations should incorporate Glickman’s treatment of rating uncertainty and related factors. One need not go as far as their everyday operational use in the US Chess Rating system. But when trying to fix something, it pays to use higher-caliber tools. This and the natural-lag and deflation above 2000 matters are of smaller magnitude than correcting the pandemic lag, however.
My Über-Recommendation
On top of all this, there is a known issue of geographical disparity in ratings, to a similar magnitude 50–100 points in many cases. I should say the following:
- I roger some of this directly, most in particular for Turkey, whose organizers deserve a gold crown for preserving complete sets of thousands of games per year by players of all ratings.
- My own IPRs for players rated below 1500 are often 100-200 points higher than their ratings. I had attributed some of this to the Chessbase database having German national ratings, not FIDE, for domestic amateur players in many large Opens, which make up much of their data for amateur players since they are a German company. German national ratings are known to be about 100 Elo deflated relative to FIDE (see paragraph after “Table 1” here).
- My main training set uses only games from the diagonals of Sonas’s charts—that is, between evenly-matched players. When I built my model afresh in early 2020, I tried to beef up the data below 1500 by using off-diagonal games there, but quickly found their noise ramped up more than their heft and so discarded them.
My model calibration below 1500 draws stability via extrapolation from higher ratings and safety from my higher variance allowance, which is determined empirically by random resampling described here. Thus while my model accords with Sonas’s observations in the large, it reopens debates on both the magnitude of the change (say between a 200 and 400 Elo “compression”) and the means of effecting it.
Sonas prefigures this kind of debate in his paper and tries to head it off. The above however leads me to cut to the chase in a way even more drastic than Sonas’s remedy, which I have been privately saying for several years:
The end of the pandemic affords a once-in-a-lifetime opportunity to reset the entire rating system around concrete and objective benchmarks.
The benchmarks could be T1 and ASD and their relatives directly, without involving my model—indeed, my “screening stage” simply combines these two metrics. Related metrics include playing one of the machine’s top 2 or 3 moves, called T2 and T3 matching, respectively, or counting any move of equal value to the first-listed move as a match, as advocated here. Many endgame positions are drawish to the extent that chess programs give optimal value 0.00 to many moves. One can hybridize these measures with ACPL or ASD, such as counting a T2 or T3 match only when the played move is within, say, 0.50 of optimal. There are variations that exclude counting positions with only one legal move or where anything but one or two moves is a major blunder.
I will, however, naturally advocate my own IPR measure as the most comprehensive benchmark. It takes many of the above hybrid considerations smoothly into account.
Linear Or Not?
Using my IPR metric—on millions of recent preserved games from around the world—would involve 10–20 times the computation I do on UB’s Center for Computational Research (CCR). That should be feasible with friendly parties. There is, however, a theoretical caveat that brings us back to our opening question:
My full model currently bakes in the status of the years 2010 to 2019 from which my training sets are drawn. It freezes the 1000-to-2800+ scale under which the raw benchmarks are nonlinear. Should this be so, or is nonlinearity what John von Neumann would call another “state of sin“?
If we bless a line like the one in my figure atop this post, which accords with Sonas’s 400 Elo “compression,” then we adopt the following projections for T1-match at the extremes:
- Zero concordance corresponds to a rating of about -1000.
- 100% concordance corresponds to about Elo 5400.
Both ends are problematic. However, zero T1-match does not mean zero skill. Nor is 100% T1-match perfection: the top programs agree only 75–80% using my settings.
The T3-match curve gives better interpretation at both ends. Using Stockfish 16 on the same dataset, the line for T3-match, using data from Elo 2000 upward, hits 0 near Elo -3250 and 100% near Elo 4000. This ceiling better accords with the Elo ratings computed for major chess programs. A floor below Elo -3000 is corroborated by curves I’ve computed for how playing quality deteriorates with less thinking time. The internal point of this diagram from my 2020 Election Day post is that the purple through red curves, which represent successively lower ratings for zero time, converge to the orange curve which uses Aitken extrapolation. The convergence becomes close when the zero-time rating falls below -3000. Moreover, a line computed by Chess.com from their data also has zero point below -3000.
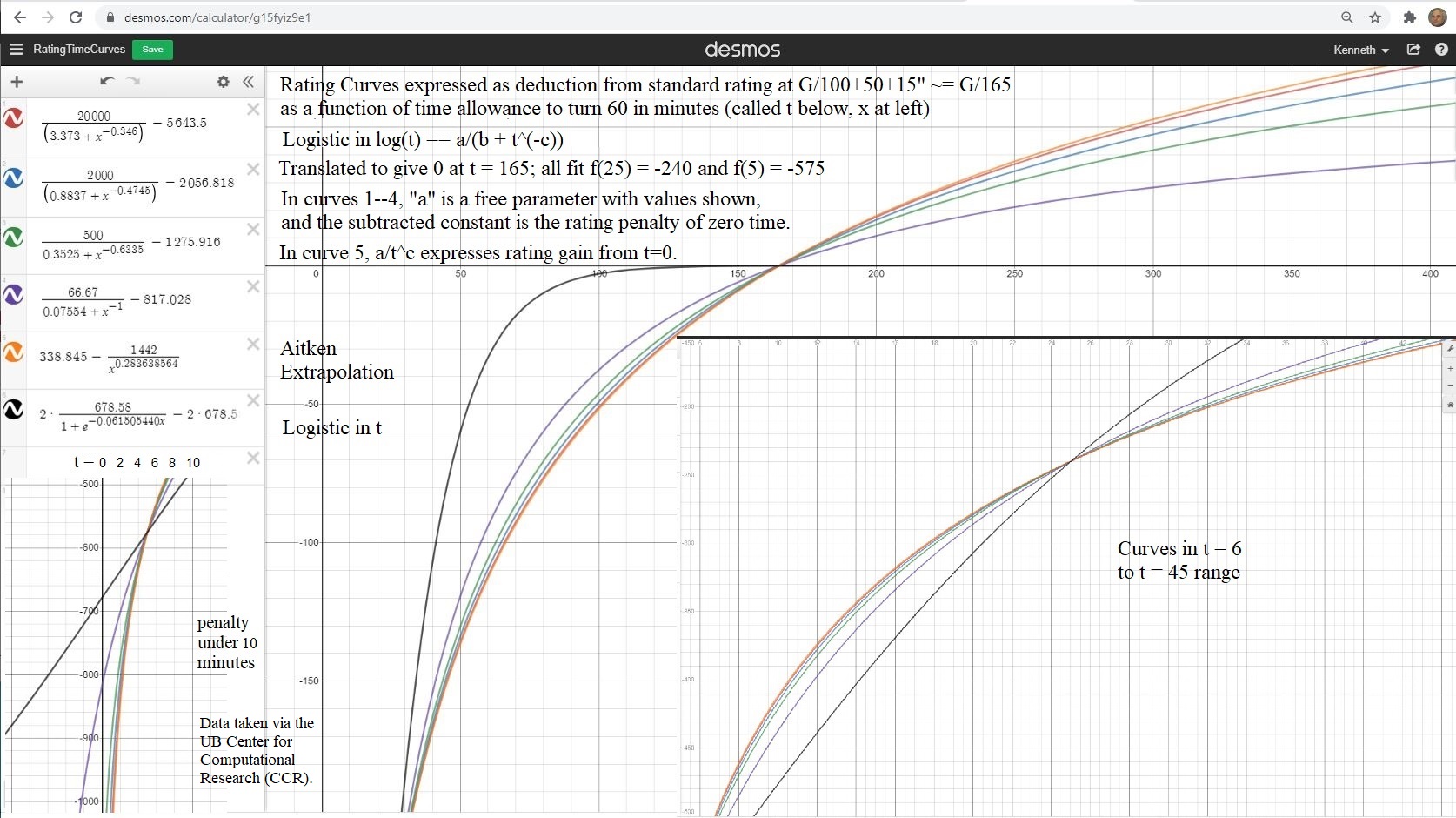{kind=link}
The average-error measures—both unscaled ACPL and my ASD—give mixed indications, as may be viewed here. They are unbounded in the direction of zero chess scale, while the ratings of their perfection points are too low. They seem more strongly linear; the hint of deviating for 1025–1200 rating may be explained by those games really being played above 1200 level. Again this accords with linearity after some form of Sonas-style “compression.”
Perhaps a definitive resolution can come from the vast corpora of games preserved online by Lichess or from particular large online events run by them or Chess.com. These platforms have their own implementations of Elo ratings. Whether game results follow the theoretical curve is just one of several filters that would be needed on this data, before metrics are plotted against ratings for games at a fixed time control.
Open Problems
FIDE have invited open discussion of measures to fix the rating system through September 30. We hope this post will promote such discussion. Most in particular, is it important to resolve the linearity issue first?
[some slight word changes, linked regression applet]