Fairness and Sampling
Gödel’s Lost Letter and P=NP 2023-10-17
A talk by Sruthi Gorantla while visiting Georgia Tech

Sruthi Gorantla is a fourth-year PhD candidate in computer science at the Indian Institute of Science and Technology in Bangalore. Her research on computational fairness is supported by a Google PhD Fellowship award and advised by Anand Louis.
Just today, Santosh Vempala announced a special talk by her for this Tuesday at Tech. The title of her talk is “Ex-Post Group Fairness and Individual Fairness in Ranking.” The abstract of her talk is:
Fair ranking tasks, which ask to rank a set of items to maximize utility subject to satisfying group-fairness constraints, have gained significant interest in algorithmic fairness, information retrieval, and machine learning literature. Recent works identify uncertainty in the utilities of items as a primary cause of unfairness and propose randomized rankings that achieve ex-ante fairer exposure and better robustness than deterministic rankings. However, this still may not guarantee representation fairness to the groups ex-post. In this talk, we will first discuss algorithms to sample a random group-fair ranking from the distribution that satisfies a set of natural axioms for randomized group-fair rankings. Our problem formulation works even when there is implicit bias, incomplete relevance information, or only an ordinal ranking is available instead of relevance scores or utility values. Next, we will look at its application to efficiently train stochastic learning-to-rank algorithms via in-processing for ex-post fairness. Finally, we will discuss an efficient algorithm that samples rankings from an individually fair distribution while ensuring ex-post group fairness.
The talk is at 11am tomorrow (Tuesday 10/17), but does not seem to be available online.
Fair Ranking Tasks
What is neat about her work is that fair-ranking tasks are a relativity new concept. In the theory of computing, progress is made on problems that have been around—in some cases—for decades. But other problems like this one are relatively new. This makes them extra exciting and raises new applications for theory work. See this among her recent papers. It is joint with Anay Mehrotra, Amit Deshpande, and Anand Louis.
The paper begins with a long literature review. It amazes us (Ken writing from here on) to see such volume of directly relevant papers in a new area. We could not begin to do the paper or its background justice writing in a short time window before the talk. (We do not know of any possible online access.) So we will say something else. It may be related—an easy reference didn’t turn up in a few searches or my glance through this long survey.
Imprecision and Bias
Suppose the “ground truth” is that entity 

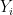
Note that an individual
This has been on my mind because it seems equivalent to issues in sporting competitions. There has been much discussion of the current Major League Baseball playoffs. All four teams that won 99 or more games in the regular season lost early in short best-of-3 or best-of-5 series. None of the four survivors won more than 90 games—and one (Arizona) won only 84 games while losing 78. A shorter series is a more-imprecise measurement of quality—and these series were shorter than the best-of-7 norm used in the World Series for over a century.
The papers on task ranking involve a utility function that grows with higher ranking place. Work on competition formats also involves a cost function for the length and nature of competition needed to achieve a target likelihood of the results reflecting the prior “ground truth.” In this, however, I incline to the view that the winner re-creates the ground truth. Hence this is not among things I’ve bugged the International Chess Federation about. In the restaurant example and many other social situations, however, imprecision is a more enduring burden.
Open Problems
See the talk if you can. How related are our remarks about bias from unavailable precision? Can clever sampling methods—akin to those in Gorantla’s work—compensate for it?