Data-structure lower bounds without encoding arguments
Thoughts 2021-06-08
I have recently posted the paper [Vio21] (download) which does something that I have been trying to do for a long time, more than ten years, on and off. Consider the basic data-structure problem of storing 
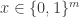
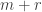

can be computed by probing 

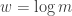

As is common in data-structure lower bounds, the proof in [PV10] is an encoding argument. In the recently posted paper, an alternative proof is presented which avoids the encoding argument and is perhaps more in line with other proofs in complexity lower bounds. Of course, everything is an encoding argument, and nothing is an encoding argument, and this post won’t draw a line.
The new proof establishes an intrinsic property of efficient data structures, whereas typical proofs including [PV10] are somewhat tailored to the problem at hand. The property is called the separator and is a main technical contribution of the work. At the high level the separator shows that in any efficient data structure you can restrict the input space a little so that many queries are nearly pairwise independent.
Also, the new proof rules out a stronger object: a sampler (see previous post here on sampling lower bounds). Specifically, the distribution Rank

Building on this machinery, one can prove several results about sampling, like showing that cell-probe samplers are strictly weaker than AC0 samplers. While doing this, it occurred to me that one gets a corollary for data structures which I had not seen in the literature. The corollary is a probe hierarchy, showing that some problem can be solved with zero redundancy (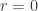



One of my favorite open problems in the area still is: can a uniform distribution over ![[m]](https://s0.wp.com/latex.php?latex=%5Bm%5D&bg=ffffff&fg=333333&s=0&c=20201002)
References
[Pǎt08] Mihai Pǎtraşcu. Succincter. In 49th IEEE Symp. on Foundations of Computer Science (FOCS). IEEE, 2008.
[PV10] Mihai Pǎtraşcu and Emanuele Viola. Cell-probe lower bounds for succinct partial sums. In 21th ACM-SIAM Symp. on Discrete Algorithms (SODA), pages 117–122, 2010.
[Vio21] Emanuele Viola. Lower bounds for samplers and data structures via the cell-probe separator. Available at http://www.ccs.neu.edu/home/viola/, 2021.
[Yu19] Huacheng Yu. Optimal succinct rank data structure via approximate nonnegative tensor decomposition. In Moses Charikar and Edith Cohen, editors, ACM Symp. on the Theory of Computing (STOC), pages 955–966. ACM, 2019.