Mathematics of the impossible: Computational Complexity, Chapter 2
Thoughts 2023-01-26
Click here for PDF version (which has better rendering of pictures, tables, etc.) Click here for all blog posts on this.
Contents
Chapter 2 The alphabet of Time

The details of the model of computation are not too important if you don’t care about power differences in running times, such as the difference between solving a problem on an input of length 
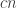
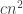
The fundamentals features of computation are two:
- Locality. Computation proceeds in small, local steps. Each step only depends on and affects a small amount of “data.” For example, in the grade-school algorithm for addition, each step only involves a constant number of digits.
- Generality. The computational process is general in that it applies to many different problems. At one extreme, we can think of a single algorithm which applies to an infinite number of inputs. This is called uniform computation. Or we can design algorithms that work on a finite set of inputs. This makes sense if the description of the algorithm is much smaller than the description of the inputs that can be processed by it. This setting is usually referred to as non-uniform computation.
Keep in mind these two principles when reading the next models.
SVG-Viewer needed.
 to
to  means that can simulate efficiently (from time
means that can simulate efficiently (from time  to
to 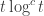 ).
).
2.1 Tape machines (TMs)
Tape machines are equipped with an infinite tape of cells with symbols from the tape alphabet
We are interested in studying the resources required for computing. Several resources are of interest, like time and space. In this chapter we begin with time.
Definition 2.1. [8]A tape machine (TM) with 
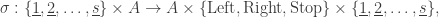
where 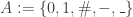
A configuration of a TM encodes its tape content, the position of the head on the tape, and the current state. It can be written as a triple 



A configuration 

![\sigma (\underline {j},\mu [i])=(a,\text {Right},\underline {j}')](https://s0.wp.com/latex.php?latex=%5Csigma+%28%5Cunderline+%7Bj%7D%2C%5Cmu+%5Bi%5D%29%3D%28a%2C%5Ctext+%7BRight%7D%2C%5Cunderline+%7Bj%7D%27%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\mu '[i]=a](https://s0.wp.com/latex.php?latex=%5Cmu+%27%5Bi%5D%3Da&bg=ffffff&fg=333333&s=0&c=20201002)


![\sigma (\underline {j},\mu [i])=(a,\text {Left},\underline {j}')](https://s0.wp.com/latex.php?latex=%5Csigma+%28%5Cunderline+%7Bj%7D%2C%5Cmu+%5Bi%5D%29%3D%28a%2C%5Ctext+%7BLeft%7D%2C%5Cunderline+%7Bj%7D%27%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\sigma (\underline {j},\mu [i])=(a,\text {Stop},\underline {j}')](https://s0.wp.com/latex.php?latex=%5Csigma+%28%5Cunderline+%7Bj%7D%2C%5Cmu+%5Bi%5D%29%3D%28a%2C%5Ctext+%7BStop%7D%2C%5Cunderline+%7Bj%7D%27%29&bg=ffffff&fg=333333&s=0&c=20201002)
We say that a TM computes 


![x=\mu [0]\mu [1]\cdots \mu [|x|-1]](https://s0.wp.com/latex.php?latex=x%3D%5Cmu+%5B0%5D%5Cmu+%5B1%5D%5Ccdots+%5Cmu+%5B%7Cx%7C-1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
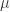

![\sigma (\mu [i],\underline {j})](https://s0.wp.com/latex.php?latex=%5Csigma+%28%5Cmu+%5Bi%5D%2C%5Cunderline+%7Bj%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
![y=\mu [i]\mu [i+1]\cdots \mu [i+|y|-1]](https://s0.wp.com/latex.php?latex=y%3D%5Cmu+%5Bi%5D%5Cmu+%5Bi%2B1%5D%5Ccdots+%5Cmu+%5Bi%2B%7Cy%7C-1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Describing TMs by giving the transition function quickly becomes complicated and uninformative. Instead, we give a high-level description of how the TM works. The important points to address are how the head moves, and how information is moved across the tape.
Example 2.1. On input 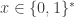
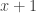




The TM only does a constant number of passes over the input, so the running time is 
Example 2.2. On an input
Since every time we do a pass we cross at least two symbols, the running time is
 in binary in time
in binary in time  .
.TMs can compute any function if they have sufficiently many states:
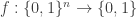 can be computed by a TM in time
can be computed by a TM in time 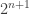 states.
states.
2.1.1 You don’t need much to have it all
How powerful are tape machines? Perhaps surprisingly, they are all-powerful.

Power-time computability thesis.
For any “realistic” computational model 
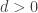
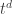
This is a thesis, not a theorem. The meaning of “realistic” is a matter of debate, and one challenge to the thesis is discussed in section º2.5.
However, the thesis can be proved for many standard computational models, which include all modern programming languages. The proofs aren’t hard. One just tediously goes through each instruction in the target model and gives a TM implementation. We prove a representative case below (Theorem 2.6) for rapid-access machines (RAMs), which are close to how computers operate, and from which the jump to a programming language is short.
Given the thesis, why bother with TMs? Why not just use RAMs or a programming language as our model? In fact, we will basically do that. Our default for complexity will be RAMs. However, some of the benefits of TMs remain
- TMs are easier to define – just imagine how more complicated Definition 2.1 would be were we to use a different model. Whereas for TMs we can give a short self-contained definition, for other models we have to resort to skipping details. There is also some arbitrariness in the definition of other models. What operations exactly are allowed?
- TMs allow us to pinpoint more precisely the limits of computation. Results such as Theorem ?? are easier to prove for TMs. A proof for RAM would first go by simulating RAM by a TM.
- Finally, TMs allow us to better pinpoint the limits of our knowledge about computation; we will see several examples of this.
In short, RAMs and programming languages are useful to carry computation, TMs to analyze it.
2.1.2 Time complexity, P, and EXP
We now define our first complexity classes. We are interested in solving a variety of computational tasks on TMs. So we make some remarks before the definition.
- We often need to compute structured objects, like tuples, graphs, matrices, etc. One can encode such objects in binary by using multiple bits. We will assume that such encodings are fixed and allow ourselves to speak of such structures objects. For example, we can encode a tuple
where
by repeating each bit in each
twice, and separate elements with
.
- We can view machines as computing functions, or solving problems, or deciding sets, or deciding languages. These are all equivalent notions. For example, for a set
, is equivalent to computing the boolean characteristic function
which outputs
- We allow partial functions, i.e., functions with a domain
that is a strict subset of
. This is a natural choice for many problems, cf. discussion in section º??.
- We measure the running time of the machine in terms of the input length, usually denoted
- We allow non-boolean outputs. However the running time is still only measured in terms of the input. (Another option which sometimes makes sense, it to bound the time in terms of the output length as well, which allows us to speak meaningfully of computing functions with very large outputs, such as exponentiation.)
- More generally, we are interested in computing not just functions but relations. That is, given an input
that belongs to a set
. For example, the problem at hand might have more than one solution, and we just want to compute any of them.
- We are only interested in sufficiently large
without worrying that it is not suitable when
, so the TM could not even get started). This is reflected in the
in the definition.
With this in mind, we now give the definition.
Definition 2.2. [Time complexity classes – boolean] Let 

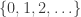


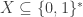

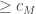
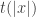


We will not need to deal with relations and partial functions until later in this text.
Also, working with boolean functions, i.e., functions 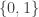
Convention about complexity classes:
Unless specified otherwise, inclusions and separations among complexity classes refer to boolean functions. For example, an expression like 


As hinted before, the definition of
2.1.3 The universal TM
Universal machines can simulate any other machine on any input. These machines play a critical role in some results we will see later. They also have historical significance: before them machines were tailored to specific tasks. One can think of such machines as epitomizing the victory of software over hardware: A single machine (hardware) can be programmed (software) to simulate any other machine.
Lemma 2.1. There is a TM 

-Stops in time 
-Outputs 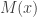
Proof. To achieve the desired speed, the idea is to maintain the invariant that

where 




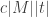
2.2 Multi-tape machines (MTMs)
Definition 2.3. A 


Exercise 2.4. Prove that Palindromes is in 
The following result implies in particular that 
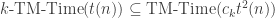 for any
for any Exercise 2.5. Prove this. Note: Use TMs as we defined them, this may make a step of the proof less obvious than it may seem.
A much less obvious simulation is given by the following fundamental result about MTMs. It shows how to reduce the number of tapes two two, at very little cost in time. Moreover, the head movements of the simulator are restricted in a sense that at first sight appears too strong.
Theorem 2.2. [3, 6]

Using this results one can prove the existence of universal MTMs similar to the universal TMs in Lemma 2.1.
2.3 Circuits
We now define circuits. It may be helpful to refer to figure 2.2 and figure 2.3.
Definition 2.4. A circuit, abbreviated Ckt, is a directed acyclic graph where each node is one of the following types: an input variable (fan-in 



An alternating circuit, abbreviated AltCkt, is a circuit with unbounded fan-in Or and And gates arranged in alternating layers (that is, the gates at a fixed distance from the input all have the same type). For each input variable
A DNF (resp. CNF) is an AltCkt whose output is Or (resp. And). The non-ouput gates are called terms (resp. clauses).



The size of a circuit is the number of gates.
Exercise 2.6. [Pushing negation gates at the input] Show that for any circuit 


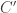

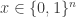

Often we will consider computing functions on small inputs. In such cases, we can often forget about details and simply appeal to the following result, which gives exponential-size circuits which are however good enough if the input is really small. In a way, the usefulness of the result goes back to the locality of computation. The result, which is a circuit analogue of Exercise 2.3, will be extensively used in this book.
Theorem 2.3. Every function 
(1) [5] circuits of size 
(2) A DNF or CNF with 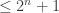
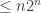
Exercise 2.7. Prove that the Or function on 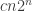
Exercise 2.8. Prove that the sum of two 
We now show that circuits can simulates TMs. We begin with a simple but instructive simulation which incurs a quadratic loss, then discuss a more complicated and sharper one.
 .
.For this proof it is convenient to represent a configuration of a TM in a slightly different way, as a string over the alphabet 

with 

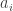
Locality of computation here means that one symbol in a string only depends on the symbols corresponding to the same tape cell
Proof of Theorem 2.4. Given a TM 

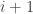


Stacking 
There remains to output the value of the function. Had we assumed that the TM writes the output in a specific cell, we could just read it off by a circuit of size 

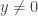
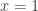
The simulation in Theorem 2.4. incurs a quadratic loss. However, a better simulation exists. In fact, this applies even to
Theorem 2.5. [6] Suppose an 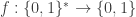

However, we won’t need it, as we will work with another model which is closer to how computers operate. And for this model we shall give a different and simpler “simulation” by circuits in Chapter ??.
In the other direction, TMs can simulate circuits if they have enough states. In general, allowing for the number of states to grow with the input length gives models with “hybrid uniformity.”
Exercise 2.10. Suppose that 
2.4 Rapid-access machines (RAMs)
“In some sense we are therefore merely making concrete intuitions that already pervade the literature. A related model has, indeed, been treated explicitly” […] [2]
The main feature that’s missing in all models considered so far is the ability to access a memory location in one time step. One can augment TMs with this capability by equipping them with an extra addressing tape and a special “jump” state which causes the head on a tape to move in one step to the address on the address tape. This model is simple enough to define, and could in a philosophical sense be the right model for how hardware can scale, since we charge for the time to write the address.
However, other models are closer to how computers seem to operate, at least over small inputs. We want to think of manipulating small integers and addresses as constant-time operations, as one typically has in mind when programming. There is a variety of such models, and some arbitrariness in their definition. Basically, we want to think of the memory as an array 
One issue that arises is how much memory the machine should have and consequently how big 
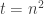
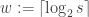
This however makes it harder to compare machines with different memory bounds. Also in some scenarios the memory size and the time bound are not fixed. This occurs for example when simulating another machine. To handle such scenarios we can start with a memory of 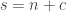
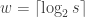
There are also two options for how the input is given to the machine. The difference doesn’t matter if you don’t care about 


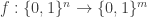
Definition 2.5. A 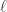
![\mu [1..s]](https://s0.wp.com/latex.php?latex=%5Cmu+%5B1..s%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Each line of the program contains an instruction among the following:
- Standard arithmetical and logical operations, such as
etc.
-
, called a Read operation, which reads the
memory cell and copies its content into
,
-
, called a Write operation, which writes
- MAlloc which increases
also increases
- Stop.
Read and write operations out of boundary indices have no effect.
On an input 


![\mu [0]](https://s0.wp.com/latex.php?latex=%5Cmu+%5B0%5D&bg=ffffff&fg=333333&s=0&c=20201002)
The output is written starting in cell
We use RAMs as our main model for time inside
 is defined as
is defined as  but for RAMs instead of TMs.
but for RAMs instead of TMs.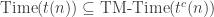 , for any
, for any What is the relationship between circuits and RAMs? If a “description” of the circuit is given, then a RAM can simulate the circuit efficiently. The other way around is not clear. It appears that circuits need a quadratic blow-up to simulate RAMs.
 but which requires circuits of size
but which requires circuits of size  .
.There are universal RAMs that can simulate any other RAM with only a constant-factor overhead, unlike the logarithmic-factor overhead for tape machines.
Lemma 2.2. There is a RAM 

-Stops in time 
-Outputs 
Proof. Throughout the computation, 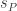


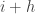
After each step, 
2.5 A challenge to the computability thesis
Today, there’s a significant challenge to the computability thesis. This challenge comes from… I know what you are thinking: Quantum computing, superposition, factoring. Nope. Randomness.
The last century or so has seen an explosion of randomness affecting much of science, and computing has been a leader in the revolution. Today, randomness permeates computation. Except for basic “core” tasks, using randomness in algorithms is standard. So let us augment our model with randomness.
Definition 2.7. A randomized (or probabilistic) RAM, written RRAM, is a RAM equipped with the extra instruction
-
, which sets
For a RRAM and a sequence 
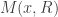


We refer to BPTime

![\mathbb {P}_{R}[M(x,R)\in f(x)]\ge 1-\epsilon (|x|)](https://s0.wp.com/latex.php?latex=%5Cmathbb+%7BP%7D_%7BR%7D%5BM%28x%2CR%29%5Cin+f%28x%29%5D%5Cge+1-%5Cepsilon+%28%7Cx%7C%29&bg=ffffff&fg=333333&s=0&c=20201002)
If the error 
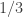
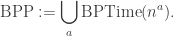
Exercise 2.13. Does the following algorithm show that deciding if a given integer 
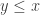
Today, one usually takes
2.5.1 Robustness of BPP: Error reduction and tail bounds for the sum of random variables
The error in the definition of BPTime is somewhat arbitrary because it can be reduced. The way you do this is natural. For boolean functions, you repeat the algorithm many times, and take a majority vote. To analyze this you need probability bounds for the sum of random variables (corresponding to the outcomes of the algorithm).
Theorem 2.7. Let 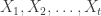
![p:=\mathbb {P}[X_{i}=1]](https://s0.wp.com/latex.php?latex=p%3A%3D%5Cmathbb+%7BP%7D%5BX_%7Bi%7D%3D1%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![\mathbb {P}[\sum _{i=1}^{t}X_{i}\ge qt]\le 2^{-D(q|p)t}](https://s0.wp.com/latex.php?latex=%5Cmathbb+%7BP%7D%5B%5Csum+_%7Bi%3D1%7D%5E%7Bt%7DX_%7Bi%7D%5Cge+qt%5D%5Cle+2%5E%7B-D%28q%7Cp%29t%7D&bg=ffffff&fg=333333&s=0&c=20201002)

is the divergence.
Now one can get a variety of bounds by bounding divergence for different settings of parameter. We state one such bound which we use shortly.
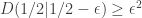 .
. Exercise 2.14. Plot both sides of Fact 2.1 as a function of
Using this bound we can prove the error reduction stated earlier.
Theorem 2.8. [Error reduction for BPP] For boolean functions, the definition of BPP (Definition 2.7) remains the same if 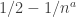


Proof. Suppose that 


This new algorithm makes a mistake iff at least 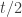
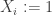


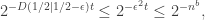
as desired. The new algorithm still runs in power time, for fixed 
Exercise 2.15. Consider an alternative definition of 


Show that defining
Exercise 2.16. Consider biased RRAMs which are like RRAMs except that the operation Rand returns one bit which, independently from all previous calls to Rand, is 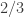
2.5.2 Does randomness buy time?
We can always brute-force the random choices in exponential time. If a randomized machine uses 
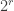



 BPTime
BPTime , for any function
, for any function 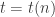 . In particular,
. In particular, 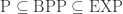 .
.
Proof. The first inclusion is by definition. The idea for the second was discussed before, but we need to address the detail that we don’t know what 
To analyze the running time, recall we only need 


Now, two surprises. First, 

However, we can do better for TMs. A randomized TMs has two transition functions 



Theorem 2.10. [9] 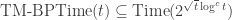

2.5.3 Polynomial identity testing
We now discuss an important problem which is in BPP but not known to be in P. In fact, in a sense to be made precise later, this is the problem in BPP which is not known to be in P. To present this problem we introduce two key concepts which will be used many times: finite fields, and arithmetic circuits.
Finite fields
A finite field 



The following summarizes key facts about finite fields. The case of prime fields suffices for the main points of this section, but stating things for general finite fields actually simplifies the exposition overall (since otherwise we need to add qualifiers to the size of the field).
Fact 2.2. [Finite fields] A unique finite field of size 

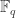
Elements in the field can be identified with 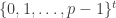
[7] Given 
Given a representation 
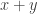


Fields of size 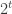
Arithmetic circuits
We now move to defining arithmetic circuits, which are a natural generalization of the circuits we encountered in section º2.3.
Definition 2.8. An arithmetic circuit over a field 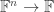
The PIT (polynomial identity testing) problem over 

The PIT problem over large fields is in
Theorem 2.11. [PIT over large fields in 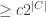

To prove this theorem we need the following fundamental fact.
Lemma 2.3. Let 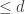


-
-
for every
-
.
Proof and discussion of Lemma 2.3. The implications 
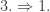


To prove the multi-variate generalization we proceed by induction on 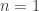
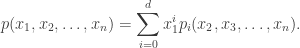
If 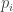


![\begin{aligned} \mathbb {P}_{x_{2},\ldots ,x_{n}\in S}[p_{j}(x)=0]\le (d-j)/|S|. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+%7BP%7D_%7Bx_%7B2%7D%2C%5Cldots+%2Cx_%7Bn%7D%5Cin+S%7D%5Bp_%7Bj%7D%28x%29%3D0%5D%5Cle+%28d-j%29%2F%7CS%7C.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
For every choice of 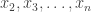
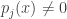

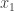
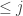
Overall,
![\begin{aligned} \mathbb {P}_{x_{1},x_{2},\ldots ,x_{n}\in S}[p(x)=0]\le (d-j)/|S|+j/|S|=d/|S|. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+%7BP%7D_%7Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Cldots+%2Cx_%7Bn%7D%5Cin+S%7D%5Bp%28x%29%3D0%5D%5Cle+%28d-j%29%2F%7CS%7C%2Bj%2F%7CS%7C%3Dd%2F%7CS%7C.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
QED
Proof of Theorem 2.11. A circuit 



Exercise 2.17. Show that the PIT problem over the integers is in BPP. (Hint: Use that the number of primes in 


The 
2.5.4 Simulating BPP by circuits
While we don’t know if
Theorem 2.12. [1]
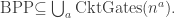
Proof. Let 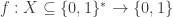
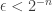
![\begin{aligned} \mathbb {P}_{R}[\exists x\in \{0,1\} ^{n}:M(x,R)\ne f(x)]\le \sum _{x\in \{0,1\}^n }\mathbb {P}_{R}[M(x,R)\ne f(x)]\le 2^{n}\cdot \epsilon <1, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+%7BP%7D_%7BR%7D%5B%5Cexists+x%5Cin+%5C%7B0%2C1%5C%7D+%5E%7Bn%7D%3AM%28x%2CR%29%5Cne+f%28x%29%5D%5Cle+%5Csum+_%7Bx%5Cin+%5C%7B0%2C1%5C%7D%5En+%7D%5Cmathbb+%7BP%7D_%7BR%7D%5BM%28x%2CR%29%5Cne+f%28x%29%5D%5Cle+2%5E%7Bn%7D%5Ccdot+%5Cepsilon+%3C1%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
where the first inequality is a union bound.
Therefore, there is a fixed choice for
Exercise 2.18. In this exercise you will practice the powerful technique of combining tail bounds with union bounds, which was used in the proof of Theorem 2.12.
An error-correcting code is a subset 



2.5.5 Questions raised by randomness
The introduction of randomness in our model raises several fascinating questions. First, does “perfect” randomness exists “in nature?” Second, do we need “perfect” randomness for computation? A large body of research has been devoted to greatly generalize Problem 2.16 to show that, in fact, even imperfect sources of randomness suffices for computation. Third, do we need randomness at all? Is
One of the exciting developments of complexity theory has been the connection between the latter question and the “grand challenge” from the next chapter. At a high level, it has been shown that explicit functions that are hard for circuits can be used to de-randomize computation. In a nutshell, the idea is that if a function is hard to compute then its output is “random,” so can be used instead of true randomness. The harder the function the less randomness we need. At one extreme, we have the following striking connection:
Theorem 2.13. [4] Suppose for some 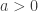


In other words, either randomness is useless for power-time computation, or else circuits can speed up exponential-time uniform computation!
2.6 Inclusion extend “upwards,” separations downwards
To develop intuition about complexity, we now discuss a general technique known as padding. In short, the technique shows that if you can trade resource 
We give a first example using the classes that we have encountered so far.
 . Then
. Then  .
.
Proof. Let 

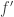


Note that 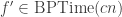
By assumption, 
To compute 
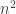
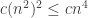
2.7 Problems
 outputs bit
outputs bit Problem 2.2. Show that Palindromes can be solved in time 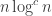
Hint: View the input as coefficients of polynomials.
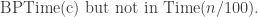
References
[1] Leonard Adleman. Two theorems on random polynomial time. In 19th IEEE Symp. on Foundations of Computer Science (FOCS), pages 75–83. 1978.
[2] Dana Angluin and Leslie G. Valiant. Fast probabilistic algorithms for hamiltonian circuits and matchings. J. Comput. Syst. Sci., 18(2):155–193, 1979.
[3] Fred Hennie and Richard Stearns. Two-tape simulation of multitape turing machines. J. of the ACM, 13:533–546, October 1966.
[4] Russell Impagliazzo and Avi Wigderson. 

[5] O. B. Lupanov. A method of circuit synthesis. Izv. VUZ Radiofiz., 1:120–140, 1958.
[6] Nicholas Pippenger and Michael J. Fischer. Relations among complexity measures. J. of the ACM, 26(2):361–381, 1979.
[7] Victor Shoup. New algorithms for finding irreducible polynomials over finite fields. Mathematics of Computation, 54(189):435–447, 1990.
[8] Alan M. Turing. On computable numbers, with an application to the entscheidungsproblem. Proc. London Math. Soc., s2-42(1):230–265, 1937.
[9] Emanuele Viola. Pseudorandom bits and lower bounds for randomized turing machines. Theory of Computing, 18(10):1–12, 2022.