Mathematics of the impossible: Computational Complexity, Chapter 3: The grand challenge
Thoughts 2023-02-02
All posts in this series. A PDF version of this post will be published with a delay, but if you’d like to have it soon let me know.
Contents
 1.4 Circuits 1.4.1 The circuit won’t fit in the universe: Non-asymptotic, cosmological results 1.5 Problems
1.4 Circuits 1.4.1 The circuit won’t fit in the universe: Non-asymptotic, cosmological results 1.5 Problems

As mentioned in Chapter ??, our ability to prove impossibility results related to efficient computation appears very limited. We can now express this situation more precisely with the models we’ve introduced since then.
- in Time
on a TM, and
- in Time
on a 2-TM, and
- by circuits of size
Note that 2. implies 1. by Theorem ??.
In this chapter we begin to present several impossibility results, covering a variety of techniques which will be used later as well. As hinted above, they appear somewhat weak. However, jumping ahead, there is a flip side to all of this:
- At times, contrary to our intuition, stronger impossibility results are actually false. One example appears in Chapter ??. A list will be given later.
- Many times, the impossibility results that we can prove turn out to be, surprisingly, just “short” of proving major results. Here by “major result” I mean a result that would be phenomenal and that was in focus long before the connection was established. We will see several examples of this (section º??, section º??).
- Yet other times, one can identify broad classes of proof techniques, and argue that impossibility results can’t be proved with them (section º??).
Given this situation, I don’t subscribe to the general belief that stronger impossibility results are true and we just can’t prove them.
1.1 Information bottleneck: Palindromes requires quadratic time on TMs
Intuitively, the weakness of TMs is the bottleneck of passing information from one end of the tape to the other. We now show how to formalize this and use it show that deciding if a string is a palindrome requires quadratic time on TMs, which is tight and likely matches the time in Exercise ??. The same bound can be shown for other functions; palindromes just happen to be convenient to obtain matching bounds.
 for any
for any  .
.More precisely, for every 

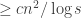
The main concept that allows us to formalize the information bottleneck mentioned above is the following.
Definition 1.1. A crossing sequence of a TM M on input 


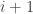
The idea in the proof is very interesting. If 


The proof that
Now, for many problems, input 
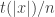
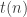
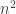
Proof. Let
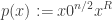
where 
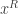
Assume there are 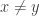
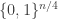
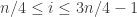

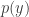

There remains to prove that the assumption of Theorem 1.1 implies the assumption in the previous paragraph. Suppose 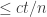
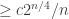
For fixed 

Hence there are 

Exercise 1.1. For every 
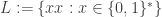 . Show
. Show 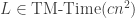 , and prove this is tight up to constants.
, and prove this is tight up to constants.One may be tempted to think that it is not hard to prove stronger bounds for similar functions. In fact as mentioned above this has resisted all attempts!
1.2 Counting: impossibility results for non-explicit functions
Proving the existence of hard functions is simple: Just count. If there are more functions than efficient machines, some function is not efficiently computable. This is applicable to any model; next we state it for TMs for concreteness. Later we will state it for circuits.
Theorem 1.2. There exists a function 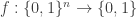

Proof. The number of TMs with 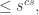

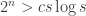
Note this bound is not far from that in Exercise ??.
It is instructive to present this basic result as an application of the probabilistic method:
Proof. Let us pick 
![\begin{aligned} \mathbb {P}_{f}[\exists \text { an }s\text {-state TM }M\text { such that }M(x)=f(x)\text { for every }x\in \{0,1\} ^{n}]<1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+%7BP%7D_%7Bf%7D%5B%5Cexists+%5Ctext+%7B+an+%7Ds%5Ctext+%7B-state+TM+%7DM%5Ctext+%7B+such+that+%7DM%28x%29%3Df%28x%29%5Ctext+%7B+for+every+%7Dx%5Cin+%5C%7B0%2C1%5C%7D+%5E%7Bn%7D%5D%3C1.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Indeed, if the probability is less than 
![\begin{aligned} \le \sum _{M}\mathbb {P}_{f}[M(x)=f(x)\text { for every }x\in \{0,1\} ^{n}], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cle+%5Csum+_%7BM%7D%5Cmathbb+%7BP%7D_%7Bf%7D%5BM%28x%29%3Df%28x%29%5Ctext+%7B+for+every+%7Dx%5Cin+%5C%7B0%2C1%5C%7D+%5E%7Bn%7D%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
where the sum is over all 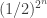


1.3 Diagonalization: Enumerating machines
Can you compute more if you have more time? For example, can you write a program that runs in time 
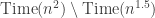 .
.The answer is more interesting if the functions are boolean. Such results are known as time hierarchies, and a generic technique for proving them is diagonalization, applicable to any model.
We first illustrate the result in the simpler case of partial functions, which contains the main ideas. Later we discuss total functions.
 such that any TM
such that any TM  , for any
, for any In other words, 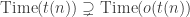
Proof. Consider the TM 


Now define 


On these inputs, 

Now suppose 
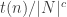



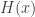

This proof is somewhat unsatisfactory; in particular we have no control on the running time of
Theorem 1.4. Let 

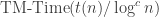
There is a total function in 

The assumption about 






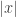
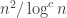
The proof is similar to that of Theorem 1.3. However, to make the function total we need to deal with arbitrary machines, which may not run in the desired time or even stop at all. The solution is to clock
Also, we define a slightly different language to give a stronger result – a unary language – and to avoid some minor technical details (the possibility that the computation of
We define a TM 

However, there are interesting differences with the simulation in Lemma ??. In that lemma the universal machine 
Whereas in Lemma ?? the tape was arranged as

it will now be arranged as

which is parsed as follows. The description of 



Proof. Define TM
- Compute
.
- Compute
. Here
is obtained from
then
. This is similar to the fact that a program does not change if you add, say, empty lines at the bottom.
- Simulate
- If
Running time of
- Computing
. Our definition of computation allows for erasing the input, but we can keep
factor. Thus we can compute
in time
- This takes time
: simply scan the input and remove zeroes.
- Decreasing the counter takes
steps. Hence this simulation will take
time.
Overall the running time is
Proof that the function computed by 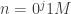

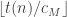

The extra 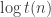
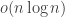
However, tighter time hierarchies hold for more powerful models, like RAMs. Also, a time hierarchy for total functions for 
Exercise 1.4. (1) State and prove a tighter time hierarchy for Time (which recall corresponds to RAMs) for total functions. You don’t need to address simulation details, but you need to explain why a sharper separation is possible.
(2) Explain the difficulty in extending (1) to
(3) State and prove a time hierarchy for
1.3.1 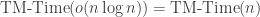
In this subsection we prove the result in the title, which we also mentioned earlier. First let us state the result formally.
 . Then
. Then 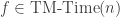 .
.Note that time
The rest of this section is devoted to proving the above theorem. Let 
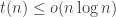 . Then on every input
. Then on every input 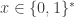 every
every 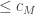 .
. Proof. For an integer 
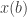



 for
for  .
.There are 
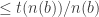


The number of such crossing sequences is

Hence, the same crossing sequence occurs at 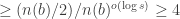

Of these four, one could be the CS of length
Lemma 1.2. Suppose 
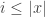


1.4 Circuits
The situation for circuits is similar to that of 2-TMs, and by Theorem ?? we know that proving 
Theorem 1.6. [3] There are functions 
One can prove a hierarchy for circuit size, by combining Theorem 1.6 and Theorem ??. As stated, the results give that circuits of size 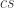
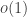
Theorem 1.7. [Hierarchy for circuit size] For every 


Proof. Consider a path from the all-zero function to a function which requires circuits of size 


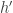
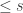
Exercise 1.7. Prove a stronger hierarchy result for alternating circuits, where the “
In fact, this improvement is possible even for (non aternating) circuits, see Problem 1.2.
1.4.1 The circuit won’t fit in the universe: Non-asymptotic, cosmological results
Most of the results in this book are asymptotic, i.e., we do not explicitly work out the constants because they become irrelevant for larger and larger input lengths. As stated, these results don’t say anything for inputs of a fixed length. For example, any function on 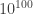
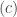
However, it is important to note that all the proofs are constructive and one can work out the constants, and produce non-asymptotic results. We state next one representative example when this was done. It is about a problem in logic, an area which often produces very hard problems.
On an alphabet of size 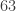





Theorem 1.8. [4] To decide the truth of logical formulas of length at most 

Their result applies even to randomized circuits with error 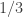

1.5 Problems
Problem 1.1. Hierarchy Theorem 1.4 only gives a function
Give a function 





Hint: Note the range of 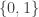
Problem 1.2. Replace “

This shows Theorem 1.5 is tight, and gives an explicit problem witnessing the time-hierarchy separation in Theorem 1.4, for a specific time bound. For the negative result, don’t use pumping lemmas or other characterization results not covered in this book.
Problem 1.4. The following argument contradicts Theorem 1.4; what is wrong with it?
 . By padding (Theorem
. By padding (Theorem 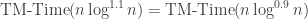 . Hence
. Hence  ”
”References
[1] F. C. Hennie. One-tape, off-line turing machine computations. Information and Control, 8(6):553–578, 1965.
[2] Kojiro Kobayashi. On the structure of one-tape nondeterministic turing machine time hierarchy. Theor. Comput. Sci., 40:175–193, 1985.
[3] Claude E. Shannon. The synthesis of two-terminal switching circuits. Bell System Tech. J., 28:59–98, 1949.
[4] Larry Stockmeyer and Albert R. Meyer. Cosmological lower bound on the circuit complexity of a small problem in logic. J. ACM, 49(6):753–784, 2002.