Mathematics of the impossible, Chapter 7, Space
Thoughts 2023-03-24
As mentioned in Chapter 2, Time is only one of several resources we with to study. Another important one is space, which is another name for the memory of the machine. Computing under space constraints may be less familiar to us than computing under time constraints, and many surprises lay ahead in this chapter that challenge our intuition of efficient computation.
If only space is under consideration, and one is OK with a constant-factor slackness, then TMs and RAMs are equivalent; much like 
We shall consider both space bounds bigger than the input length and smaller. For the latter, we have to consider the input separately. The machine should be able to read the input, but not write on its cells. One way to formalize this is to consider 2TMs, where one tape holds the input and is read-only. The other is a standard read-write tape.
We also want to compute functions 




Definition 7.1. A function 





We define:

We investigate next some basic relationship between space and time.
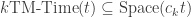 ,
, ,
, .
. Proof. 1. A TM running in time 
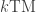
2. A RAM running in time 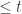


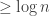
We also allocate
3. On an input 


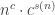

A non-trivial saving is given by the following theorem.
Theorem 7.2. [12] 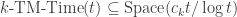
This result is not specific to MTMs but can be proved for other models such as RAMs.
From Theorem 7.1 and the next exercise we have
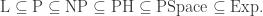
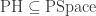 .
. Just like for Time, for space one has universal machines and a hierarchy theorem. The latter implies 
7.1 Branching programs
Branching programs are the non-uniform counterpart of 
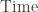
Definition 7.2. A (branching) program is a directed acyclic graph. A node can be labeled with an input variable, in which case it has two outgoing edges labeled 
The space of the program with 




Theorem 7.3. Suppose a 2TM 


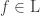

Proof. Each node in the program corresponds to a configuration. QED
Definition 7.3. The branching program given by Theorem 7.3 is called the configuration graph of
The strongest available impossibility result for branching programs is the following.
Theorem 7.4. [16] There are explicit functions (in 
7.2 The power of L
Computing with severe space bounds, as in L, seems quite difficult. Also, it might be somewhat less familiar than, say, computing within a time bound. It turns out that L is a powerful class capable of amazing computational feats that challenge our intuition of efficient computation. Moreover, these computational feats hinge on deep mathematical techniques of wide applicability. We hinted at this in Chapter 1. We now give further examples. At the same time we develop our intuition of what is computable with little space.
To set the stage, we begin with a composition result. In the previous sections we used several times the simple result that the composition of two maps in P is also in P. This is useful as it allows us to break a complicated algorithm in small steps to be analyzed separately – which is a version of the divide et impera paradigm. A similar composition result holds and is useful for space, but the argument is somewhat less obvious.
Lemma 7.1. Let 





Then the composed function 


In particular, if 
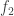


7.2.1 Arithmetic
A first example of the power of L is given by its ability to perform basic arithmetic. Grade school algorithms use a lot of space, for example they employ space 
Theorem 7.5. The following problems are in L:
- Addition of two input integers.
- Iterated addition: Addition of any number of input integers.
- Multiplication of two input integers.
- Iterated multiplication: Multiplication of any number of input integers.
- Division of two integers.
Iterated multiplication is of particular interest because it can be used to compute “pseudorandom functions.” Such objects shed light on our ability to prove impossibility results via the “Natural Proofs” connection which we will see in Chapter ??.
Proof of 1. in Theorem 7.5. We are given as input 
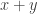

Exercise 7.3. Prove 2. and 3. in Theorem 7.5.
Proving 4. and 5. is more involved and requires some of those deep mathematical tools of wide applicability we alluded to before. Division can be computed once we can compute iterated multiplication. In a nutshell, the idea is to use the expansion

We omit details about bounding the error. Instead, we point out that this requires computing powers 
So for the rest of this section we focus on iterated multiplication. Our main tool for this the Chinese-remaindering representation of integers, abbreviated CRR.
Definition 7.4. We denote by 
Theorem 7.6. Let 

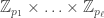
The forward direction of the isomorphism is given by the map

For the converse direction, there exist integers 
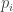

Each integer 

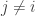
Example 7.1. 


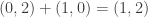

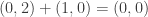
To compute iterated multiplication the idea is to move to CRR, perform the multiplications there, and then move back to standard representation. A critical point is that each coordinate in the CRR has a representation of only 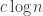
The algorithm is as follows:
 . [6]
. [6]
- Let
and compute the first
prime numbers
.
- Convert the input into CRR: Compute
.
- Compute the multiplications in CRR:
.
- Convert back to standard representation.
Now we explain how steps 1, 2, and 3 can be implemented in L. Step 4 can be implemented in L too, but showing this is somewhat technical due to the computation of the numbers
Step 1
By Theorem ??, the primes 
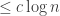

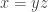

Step 2
We explain how given 
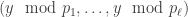


Step 3
This is a smaller version of the original problem: for each 

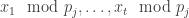

Step 4
By Theorem 7.6, to convert back to standard representation from CRR we have to compute the map
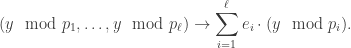
Assuming we can compute the
Putting the steps together
Combining the steps together we can compute iterated multiplication in L as long as we are given the integers
Theorem 7.7. Given integers 



In particular, because the 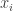
Exercise 7.5. Show that given integers 

in L. You cannot use the fact that iterated multiplication is in L, a result which we stated but not completely proved.
Exercise 7.6. Show that the iterated multiplication of 

7.2.2 Graphs
We now give another example of the power of L.
Definition 7.5. The undirected reachability problem: Given an undirected graph 
Standard time-efficient algorithms to solve this problem mark nodes in the graph. In logarithmic space we can keep track of a constant number of nodes, but it is not clear how we can avoid repeating old steps forever.
Theorem 7.8. [20] Undirected reachability is in L.
The idea behind this result is that a random walk on the graph will visit every node, and can be computed using small space, since we just need to keep track of the current node. Then, one can derandomize the random walk and obtain a deterministic walk, again computable in L.
7.2.3 Linear algebra
Our final example comes from linear algebra. Familiar methods for solving a linear system

can be done requires a lot of space. For example using elimination we need to rewrite the matrix 
Theorem 7.9. [9] Solving a linear system is computable in 
7.3 Checkpoints
The checkpoint technique is a fundamental tool in the study of space-bounded computation. Let us illustrate it at a high level. Let us consider a graph 


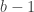

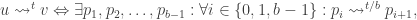 where we denote
where we denote  and
and  .
. An important aspect of this technique is that it can be applied recursively: We can apply it again to the problems 

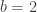

We now utilize the checkpoint technique to show a simulation of small-space computation by small-depth alternating circuits.
Theorem 7.10. A function computable by a branching program with 


To illustrate the parameters, suppose 
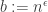
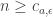


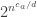
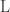

in has alternating circuits of depth and size 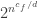 . (2) We can prove that there are explicit functions (also in L) which cannot be computed by circuits of depth and size . (3) Improving the constant in the double exponent for a function in P would yield
. (2) We can prove that there are explicit functions (also in L) which cannot be computed by circuits of depth and size . (3) Improving the constant in the double exponent for a function in P would yield  . In this sense, the result in (2) is the best possible short of proving a major separation.
. In this sense, the result in (2) is the best possible short of proving a major separation. Proof. We apply the checkpoint technique to the branching program, recursively, with parameter 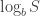
In one application, we have an 
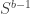


Each leaf can be connected to the input bit on which it depends. The size of the circuit is at most 
If 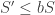
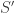
The following is a uniform version of Theorem 7.10, and the proof is similar. It shows that we can speed up space-bounded computation with alternations.
Theorem 7.11. [17]Any 

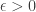
Proof. Let 
We apply to this graph the checkpoint technique recursively, with parameter 


Each quantifier ranges over 
There remains to check a path of length 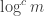


We note that by the generic simulation of alternating time by small-depth circuits in Lemma 6.2, the above theorem also gives a result similar to Theorem 7.10.
7.4 Reductions: L vs. P
Again, we can use reductions to related the space complexity of problems. In particular we can identify the problems in P which have space-efficient algorithms iff every problem in P does.
 and
and  .
. Proof. Circuit value is in P since we can evaluate one gate at the time. Now let 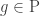
Definition 7.8. The monotone circuit value problem: Given a circuit 
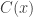
Recall from section 7.2.3 that finding solutions to linear systems
has space-efficient algorithms. Interestingly, if we generalize equalities to inequalities the problem becomes P complete. This set of results illustrates a sense in which “linear algebra” is easier than “optimization.”
Definition 7.9. The linear inequalities problem: Given a 
Proof. The ellipsoid algorithm shows that Linear inequalities is in P, but we will not discuss this classic result.
Instead, we focus on showing how given a circuit 
We shall have as many variables 
For an input gate 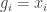

For a Not gate 

For an And gate 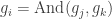
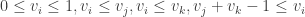
The case of Or is similar, or can be dispensed by writing an Or using Not and And.
Finally, if 

We claim that in every solution to 
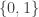
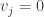


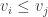

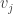


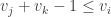
7.4.1 Nondeterministic space
Because of the insight we gained from considering non-deterministic time-bounded computation in section º5.1, we are naturally interested in non-deterministic space-bounded computation. In fact, perhaps we will gain even more insight, because this notion will really challenge our understanding of computation.
For starters, let us define non-deterministic space-bounded computation. A naive approach is to define it using the quantifiers from section º6.4, leading to the class 
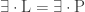 .
.Instead, non-deterministic space is defined in terms of non-deterministic TMs.
Definition 7.10. A function 

1. The machine is equipped with a special “Guess” state. Upon entering this state, a guess bit is written on the work tape under the head.
2. 
We define
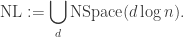
How can we exploit this non-determinism? Recall from section 7.2.2 that reachability in undirected graphs is in L. It is unknown if the same holds for directed graphs. However, we can solve it in NL.
Definition 7.11. The directed reachability problem: Given a directed graph
Proof. The proof simply amounts to guessing a path in the graph. The algorithm is as follows:
“On input 

For 
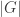
If 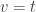
Guess a neighbor 

If you haven’t accepted, reject.”
The space needed is 
We can define NL completeness similarly to NP and P completeness, and have the following result.
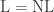 .
.7.4.2 Nspace vs. time
Recall by definition 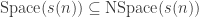

 .
. Proof. On input x, we compute the configuration graph
The next theorem shows that non-deterministic space is not much more powerful than deterministic space: it buys at most a square. Contrast this with the P vs. NP question! The best determistic simulation of NP that we know is the trivial 
How can this be possible? The high-level idea, which was used already in Lemma 7.1, can be cast as follows:
Theorem 7.17. [23] 


Proof. We use the checkpoint technique with parameter 
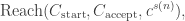
where 
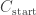


The key point is how to implement Reach.

For all “middle” configurations
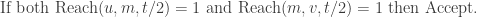
Reject
Let 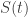
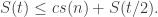
This is because we can re-use the space for two calls to Reach. Therefore, the space for 

QED
Recall that we do not know if 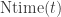
What about space? Is 
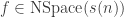

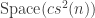
Can we avoid squaring the space?
Yes! This is weird!
Proof. We want a non-deterministic 2TM that given 
For starters, suppose the machine has computed the number
to , given :
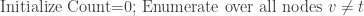

If 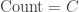
There remains to compute
Let 
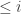



To compute 
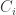
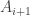

The enumeration over
7.5 TiSp
So far in this chapter we have focused on bounding the space usage. For this, the TM model was sufficient, as remarked at the beginning. It is natural to consider algorithms that operate in little time and space. For this, of course, whether we use TMs or RAMs makes a difference.
Definition 7.12. Let 

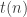
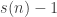
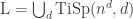 .
. An alternative definition of TiSp would allow the RAM to access
To illustrate the relationship between TiSp, Time, and Space, consider undirected reachability. It is solvable in Time


Exercise 7.11. Prove that Theorem 7.11 holds even for any function 
The following is a non-uniform version of TiSp.
Definition 7.13. A branching program of length 



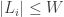
Thus 
Recall that Theorem 7.10 gives bounds of the form 



With these definitions in hand we can refine the connection between branching programs and small-depth circuits in Theorem 7.10 for circuits of depth 3.
Theorem 7.19. Let 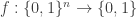

We will later show explicit functions that require depth-3 circuits of size 
7.6 Notes
For a discussion of the complexity of division, see [3]. For a compendium of P-complete problems see [11].
References
[1] Mikl≤s Ajtai. 
[2] Mikl≤s Ajtai. A non-linear time lower bound for boolean branching programs. Theory of Computing, 1(1):149–176, 2005.
[3] Eric Allender. The division breakthroughs. Bulletin of the EATCS, 74:61–77, 2001.
[4] Noga Alon, Oded Goldreich, Johan Hσstad, and RenΘ Peralta. Simple constructions of almost 
[5] Kenneth E. Batcher. Sorting networks and their applications. In AFIPS Spring Joint Computing Conference, volume 32, pages 307–314, 1968.
[6] Paul Beame, Stephen A. Cook, and H. James Hoover. Log depth circuits for division and related problems. SIAM J. Comput., 15(4):994–1003, 1986.
[7] Paul Beame, Michael Saks, Xiaodong Sun, and Erik Vee. Time-space trade-off lower bounds for randomized computation of decision problems. J. of the ACM, 50(2):154–195, 2003.
[8] Stephen A. Cook. A hierarchy for nondeterministic time complexity. J. of Computer and System Sciences, 7(4):343–353, 1973.
[9] L. Csanky. Fast parallel matrix inversion algorithms. SIAM J. Comput., 5(4):618–623, 1976.
[10] Aviezri S. Fraenkel and David Lichtenstein. Computing a perfect strategy for n x n chess requires time exponential in n. J. Comb. Theory, Ser. A, 31(2):199–214, 1981.
[11] Raymond Greenlaw, H. James Hoover, and Walter Ruzzo. Limits to Parallel Computation: P-Completeness Theory. 02 2001.
[12] John E. Hopcroft, Wolfgang J. Paul, and Leslie G. Valiant. On time versus space. J. ACM, 24(2):332–337, 1977.
[13] Richard M. Karp and Richard J. Lipton. Turing machines that take advice. L’Enseignement MathΘmatique. Revue Internationale. IIe SΘrie, 28(3-4):191–209, 1982.
[14] Leonid A. Levin. Universal sequential search problems. Problemy Peredachi Informatsii, 9(3):115–116, 1973.
[15] Joseph Naor and Moni Naor. Small-bias probability spaces: efficient constructions and applications. SIAM J. on Computing, 22(4):838–856, 1993.
[16] E. I. Nechiporuk. A boolean function. Soviet Mathematics-Doklady, 169(4):765–766, 1966.
[17] Valery A. Nepomnjaščiĭ. Rudimentary predicates and Turing calculations. Soviet Mathematics-Doklady, 11(6):1462–1465, 1970.
[18] NEU. From RAM to SAT. Available at http://www.ccs.neu.edu/home/viola/, 2012.
[19] Wolfgang J. Paul, Nicholas Pippenger, Endre SzemerΘdi, and William T. Trotter. On determinism versus non-determinism and related problems (preliminary version). In IEEE Symp. on Foundations of Computer Science (FOCS), pages 429–438, 1983.
[20] Omer Reingold. Undirected connectivity in log-space. J. of the ACM, 55(4), 2008.
[21] J. M. Robson. N by N checkers is exptime complete. SIAM J. Comput., 13(2):252–267, 1984.
[22] Rahul Santhanam. On separators, segregators and time versus space. In IEEE Conf. on Computational Complexity (CCC), pages 286–294, 2001.
[23] Walter J. Savitch. Relationships between nondeterministic and deterministic tape complexities. Journal of Computer and System Sciences, 4(2):177–192, 1970.
[24] Michael Sipser. A complexity theoretic approach to randomness. In ACM Symp. on the Theory of Computing (STOC), pages 330–335, 1983.
[25] Seinosuke Toda. PP is as hard as the polynomial-time hierarchy. SIAM J. on Computing, 20(5):865–877, 1991.
[26] Leslie G. Valiant and Vijay V. Vazirani. NP is as easy as detecting unique solutions. Theor. Comput. Sci., 47(3):85–93, 1986.
[27] N. V. Vinodchandran. A note on the circuit complexity of PP. Theor. Comput. Sci., 347(1-2):415–418, 2005.
[28] Emanuele Viola. On approximate majority and probabilistic time. Computational Complexity, 18(3):337–375, 2009.