Mathematics of the impossible, Chapter 12, Data structures
Thoughts 2023-05-14
And as promised, here’s a chapter on data structures… in a complexity theory course! — Data structures aim to maintain data in memory so as to be able to support various operations, such as answering queries about the data, and updating the data. The study of data structures is fundamental and extensive. We distinguish and study in turn two types of data structure problems: static and dynamic. In the former the input is given once and cannot modified by the queries. In the latter queries can modify the input; this includes classical problems such as supporting insert, search, and delete of keys.
12.1 Static data structures
Definition 12.1. A static data-structure problem is simply a function ![f:\{0,1\}^n \to [q]^{m}](https://s0.wp.com/latex.php?latex=f%3A%5C%7B0%2C1%5C%7D%5En+%5Cto+%5Bq%5D%5E%7Bm%7D&bg=ffffff&fg=333333&s=0&c=20201002)





where ![g:\{0,1\} ^{n}\to [2^{w}]^{s}](https://s0.wp.com/latex.php?latex=g%3A%5C%7B0%2C1%5C%7D+%5E%7Bn%7D%5Cto+%5B2%5E%7Bw%7D%5D%5E%7Bs%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![h:[2^{w}]^{s}\to [q]^{m}](https://s0.wp.com/latex.php?latex=h%3A%5B2%5E%7Bw%7D%5D%5E%7Bs%7D%5Cto+%5Bq%5D%5E%7Bm%7D&bg=ffffff&fg=333333&s=0&c=20201002)

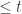
Here we have 


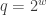

Exercise 12.1. Consider the data structure problem 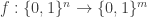




Give a data structure for this problem with 

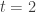
Exercise 12.2. Show that any data-structure problem
(1) 
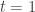
(2) 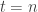
Exercise 12.3. Prove that for every 


By contrast, next we present the the best known impossibility result.
Definition 12.2. A function ![f:[2]^{n}\to [q]^{m}](https://s0.wp.com/latex.php?latex=f%3A%5B2%5D%5E%7Bn%7D%5Cto+%5Bq%5D%5E%7Bm%7D&bg=ffffff&fg=333333&s=0&c=20201002)

Theorem 12.1. [65] Let ![f:[q]^{d}\to [q]^{q}](https://s0.wp.com/latex.php?latex=f%3A%5Bq%5D%5E%7Bd%7D%5Cto+%5Bq%5D%5E%7Bq%7D&bg=ffffff&fg=333333&s=0&c=20201002)




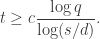
Interpreting the input as coefficients of a degree 
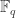
To match previous parameters note that 

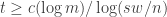

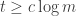
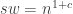

Proof. The idea in the proof is to find a subset 
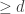
Let 

![\mathbb {P}[|S|\ge cps]\le 2^{-cps}](https://s0.wp.com/latex.php?latex=%5Cmathbb+%7BP%7D%5B%7CS%7C%5Cge+cps%5D%5Cle+2%5E%7B-cps%7D&bg=ffffff&fg=333333&s=0&c=20201002)
We are still able to answer a query if all of its memory bits fall in 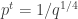



![\mathbb {E}[|B|]\le q(1-q^{1/4})](https://s0.wp.com/latex.php?latex=%5Cmathbb+%7BE%7D%5B%7CB%7C%5D%5Cle+q%281-q%5E%7B1%2F4%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)
![\begin{aligned} \mathbb {P}[B\ge q(1-1/\sqrt {q})]\le \frac {1-q^{1/4}}{1-\sqrt {q}}\le 1-q^{c}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+%7BP%7D%5BB%5Cge+q%281-1%2F%5Csqrt+%7Bq%7D%29%5D%5Cle+%5Cfrac+%7B1-q%5E%7B1%2F4%7D%7D%7B1-%5Csqrt+%7Bq%7D%7D%5Cle+1-q%5E%7Bc%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Thus, if the inequality 


 ="" Because
="" Because 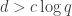 by assumption, and increasing only make the problem easier, we reach a contradiction if
by assumption, and increasing only make the problem easier, we reach a contradiction if 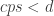 , and="" the="" result="" follows.="" QED
, and="" the="" result="" follows.="" QED
Next we show a conceptually simple data structure which nearly matches the lower bound. For simplicity we focus on data structures which use space 

Theorem 12.2. There is a map 
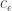

To give a sense of the parameters, let for example 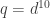
Proof. We fill the memory with 


![R\subseteq [q]](https://s0.wp.com/latex.php?latex=R%5Csubseteq+%5Bq%5D&bg=ffffff&fg=333333&s=0&c=20201002)

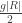
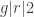
Note here we are using that the neighborhood has size 
We pick the graph at random and show that it has the latter property with non-zero probability. [Standard calculations follow that wordpress has trouble displaying… wait for the book draft, I guess.] QED
12.1.1 Succinct data structures
Succinct data structures are those where the space is close to the minimum, 

To illustrate, consider the ECC problem
Theorem 12.3. [26] Any data-structure for the ECC problem with 

This is nearly matched by the following result.
Theorem 12.4. [81] There is an ECC problem s.t. for any 

Moreover, it was shown that proving a time lower bound of 
Theorem 12.5. [81] Let 





Hence, proving 
12.1.2 Succincter: The trits problem
In this section we present a cute and fundamental data-structure problem with a shocking and counterintuitive solution. The trits problem is to compute ![f:[3]^{n}\to (\{0,1\} ^{2})^{n}](https://s0.wp.com/latex.php?latex=f%3A%5B3%5D%5E%7Bn%7D%5Cto+%28%5C%7B0%2C1%5C%7D+%5E%7B2%7D%29%5E%7Bn%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![(t_{1},t_{2},\ldots ,t_{n})\in [3]^{n}](https://s0.wp.com/latex.php?latex=%28t_%7B1%7D%2Ct_%7B2%7D%2C%5Cldots+%2Ct_%7Bn%7D%29%5Cin+%5B3%5D%5E%7Bn%7D&bg=ffffff&fg=333333&s=0&c=20201002)
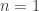 , we have
, we have 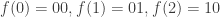 .
. Note that the input ranges over 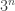
Simple solutions:
- The simplest solution (cf. 12.2) to this problem is to use
. With such an encoding we can retrieve each
by reading just
and we have linear redundancy.
- Another solution (cf. again 12.2) to this problem is what is called arithmetic coding: we think of the concatenated elements as forming a ternary number between
and
, and we write down its binary representation. To retrieve
- For this and other problems, we can trade between these two extreme as follows. Group the
bits and the needed space will be
(assuming
into
.)
The shocking solution: An exponential (!) trade-off
We now present an exponential trade-off: retrieval time 

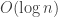
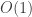

Theorem 12.6. [53, 21] The trits problem has a data structure with space 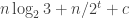
Next we present the proof.
Definition 12.3 (Encoding and redundancy). An encoding of a set 
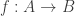

The following lemma gives the building-block encoding we will use.
Lemma 12.1. For all sets 




such that (1) 

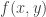
Note that (1) says that 

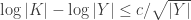


The basic idea for proving the lemma is to break 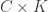


There is however a subtle point. If we insist on always having 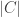



Proof. Pick any two sets 


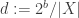

How much can we stuff into 

To calculate the total redundancy, we still need to examine the encoding from 
The total redundancy is then 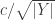
For (2), it is clear from the construction that any
Proof of Theorem 12.6. Break the ternary elements into blocks of size 
![T_{i}=[3]^{t}](https://s0.wp.com/latex.php?latex=T_%7Bi%7D%3D%5B3%5D%5E%7Bt%7D&bg=ffffff&fg=333333&s=0&c=20201002)
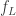
Compute 
For 

Encode 
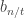
The final encoding is 
Redundancy: From (1) in Lemma 12.1, the first 



Retrieval Time: Say that we want to recover some 

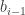
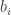

This is not completely obvious because one might have thought that the 

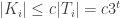

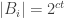

QED
12.2 Dynamic data structures
We now study dynamic data structures. As we mentioned, here the input is not fixed but can be modified by the queries.
Definition 12.4. Fix an error-correcting code 

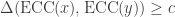
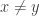

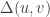


The 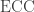





The time of a dynamic data structure is the maximum number of read/write operations in memory cells required to support an operation.
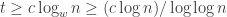 for cell size
for cell size  .
.One might wonder if stronger bounds can be shown for this problem. But in fact there exist codes for which the bounds are nearly tight.
Theorem 12.8. [81]There exists codes for which the ECC problem can be solved in time 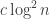
The technique in the proof of Theorem 12.7 is from [24] and can be applied to many other natural problems, leading to tight results in several cases, see Exercise ??. It is not far from the state-of-the art in this area, which is 
Proof of Theorem 12.7. Pick
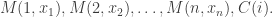
That is, we set the message to a uniform 
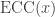

We divide the 



The geometrically decaying size of epochs is chosen so that the number of message bits set during an epoch
A key idea of the proof is to see what happens when the cells written during a certain epoch are ignored, or reverted to their contents right before the epoch. Specifically, after the execution of the 
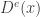

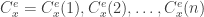
Let 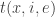

where the last inequality holds because 

We now claim that if 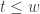

In the remainder we justify the claim. Fix arbitrarily the bits of

codewords. On the other hand, we claim that 

We can describe all these cells by writing down their indices and contents using 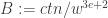

For each string in the range of 

Hence except with probability 



12.3 Notes
The exposition of the trits problem is from [76].
References
[1] Amir Abboud, Arturs Backurs, and Virginia Vassilevska Williams. Tight hardness results for LCS and other sequence similarity measures. In Venkatesan Guruswami, editor, IEEE 56th Annual Symposium on Foundations of Computer Science, FOCS 2015, Berkeley, CA, USA, 17-20 October, 2015, pages 59–78. IEEE Computer Society, 2015.
[2] Leonard Adleman. Two theorems on random polynomial time. In 19th IEEE Symp. on Foundations of Computer Science (FOCS), pages 75–83. 1978.
[3] Mikl�s Ajtai. 
[4] Mikl�s Ajtai. A non-linear time lower bound for boolean branching programs. Theory of Computing, 1(1):149–176, 2005.
[5] Eric Allender. A note on the power of threshold circuits. In 30th Symposium on Foundations of Computer Science, pages 580–584, Research Triangle Park, North Carolina, 30 October–1 November 1989. IEEE.
[6] Eric Allender. The division breakthroughs. Bulletin of the EATCS, 74:61–77, 2001.
[7] Eric Allender and Michal Koucký. Amplifying lower bounds by means of self-reducibility. J. of the ACM, 57(3), 2010.
[8] Noga Alon, Oded Goldreich, Johan H�stad, and Ren� Peralta. Simple constructions of almost 
[9] Dana Angluin and Leslie G. Valiant. Fast probabilistic algorithms for hamiltonian circuits and matchings. J. Comput. Syst. Sci., 18(2):155–193, 1979.
[10] Sanjeev Arora, Carsten Lund, Rajeev Motwani, Madhu Sudan, and Mario Szegedy. Proof verification and the hardness of approximation problems. J. of the ACM, 45(3):501–555, May 1998.
[11] Arturs Backurs and Piotr Indyk. Edit distance cannot be computed in strongly subquadratic time (unless SETH is false). SIAM J. Comput., 47(3):1087–1097, 2018.
[12] Kenneth E. Batcher. Sorting networks and their applications. In AFIPS Spring Joint Computing Conference, volume 32, pages 307–314, 1968.
[13] Paul Beame, Stephen A. Cook, and H. James Hoover. Log depth circuits for division and related problems. SIAM J. Comput., 15(4):994–1003, 1986.
[14] Paul Beame, Michael Saks, Xiaodong Sun, and Erik Vee. Time-space trade-off lower bounds for randomized computation of decision problems. J. of the ACM, 50(2):154–195, 2003.
[15] Michael Ben-Or and Richard Cleve. Computing algebraic formulas using a constant number of registers. SIAM J. on Computing, 21(1):54–58, 1992.
[16] Samuel R. Buss and Ryan Williams. Limits on alternation trading proofs for time-space lower bounds. Comput. Complex., 24(3):533–600, 2015.
[17] Lijie Chen and Roei Tell. Bootstrapping results for threshold circuits “just beyond” known lower bounds. In Moses Charikar and Edith Cohen, editors, Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, STOC 2019, Phoenix, AZ, USA, June 23-26, 2019, pages 34–41. ACM, 2019.
[18] Richard Cleve. Towards optimal simulations of formulas by bounded-width programs. Computational Complexity, 1:91–105, 1991.
[19] Stephen A. Cook. A hierarchy for nondeterministic time complexity. J. of Computer and System Sciences, 7(4):343–353, 1973.
[20] L. Csanky. Fast parallel matrix inversion algorithms. SIAM J. Comput., 5(4):618–623, 1976.
[21] Yevgeniy Dodis, Mihai Pǎtraşcu, and Mikkel Thorup. Changing base without losing space. In 42nd ACM Symp. on the Theory of Computing (STOC), pages 593–602. ACM, 2010.
[22] Lance Fortnow. Time-space tradeoffs for satisfiability. J. Comput. Syst. Sci., 60(2):337–353, 2000.
[23] Aviezri S. Fraenkel and David Lichtenstein. Computing a perfect strategy for n x n chess requires time exponential in n. J. Comb. Theory, Ser. A, 31(2):199–214, 1981.
[24] Michael L. Fredman and Michael E. Saks. The cell probe complexity of dynamic data structures. In ACM Symp. on the Theory of Computing (STOC), pages 345–354, 1989.
[25] Anka Gajentaan and Mark H. Overmars. On a class of 
[26] Anna G�l and Peter Bro Miltersen. The cell probe complexity of succinct data structures. Theoretical Computer Science, 379(3):405–417, 2007.
[27] M. R. Garey and David S. Johnson. Computers and Intractability: A Guide to the Theory of NP-Completeness. W. H. Freeman, 1979.
[28] K. G�del. �ber formal unentscheidbare s�tze der Principia Mathematica und verwandter systeme I. Monatsh. Math. Phys., 38, 1931.
[29] Oded Goldreich. Computational Complexity: A Conceptual Perspective. Cambridge University Press, 2008.
[30] Raymond Greenlaw, H. James Hoover, and Walter Ruzzo. Limits to Parallel Computation: P-Completeness Theory. 02 2001.
[31] David Harvey and Joris van der Hoeven. Integer multiplication in time 
[32] F. C. Hennie. One-tape, off-line turing machine computations. Information and Control, 8(6):553–578, 1965.
[33] Fred Hennie and Richard Stearns. Two-tape simulation of multitape turing machines. J. of the ACM, 13:533–546, October 1966.
[34] John E. Hopcroft, Wolfgang J. Paul, and Leslie G. Valiant. On time versus space. J. ACM, 24(2):332–337, 1977.
[35] Russell Impagliazzo and Ramamohan Paturi. The complexity of
[36] Russell Impagliazzo, Ramamohan Paturi, and Michael E. Saks. Size-depth tradeoffs for threshold circuits. SIAM J. Comput., 26(3):693–707, 1997.
[37] Russell Impagliazzo, Ramamohan Paturi, and Francis Zane. Which problems have strongly exponential complexity? J. Computer & Systems Sciences, 63(4):512–530, Dec 2001.
[38] Russell Impagliazzo and Avi Wigderson. 

[39] Richard M. Karp and Richard J. Lipton. Turing machines that take advice. L’Enseignement Math�matique. Revue Internationale. IIe S�rie, 28(3-4):191–209, 1982.
[40] Kojiro Kobayashi. On the structure of one-tape nondeterministic turing machine time hierarchy. Theor. Comput. Sci., 40:175–193, 1985.
[41] Swastik Kopparty and Srikanth Srinivasan. Certifying polynomials for AC\({}^{\mbox {0}}\)[\(\oplus \)] circuits, with applications to lower bounds and circuit compression. Theory of Computing, 14(1):1–24, 2018.
[42] Kasper Green Larsen, Omri Weinstein, and Huacheng Yu. Crossing the logarithmic barrier for dynamic boolean data structure lower bounds. SIAM J. Comput., 49(5), 2020.
[43] Leonid A. Levin. Universal sequential search problems. Problemy Peredachi Informatsii, 9(3):115–116, 1973.
[44] Carsten Lund, Lance Fortnow, Howard Karloff, and Noam Nisan. Algebraic methods for interactive proof systems. J. of the ACM, 39(4):859–868, October 1992.
[45] O. B. Lupanov. A method of circuit synthesis. Izv. VUZ Radiofiz., 1:120–140, 1958.
[46] Wolfgang Maass and Amir Schorr. Speed-up of Turing machines with one work tape and a two-way input tape. SIAM J. on Computing, 16(1):195–202, 1987.
[47] David A. Mix Barrington. Bounded-width polynomial-size branching programs recognize exactly those languages in NC1. J. of Computer and System Sciences, 38(1):150–164, 1989.
[48] Joseph Naor and Moni Naor. Small-bias probability spaces: efficient constructions and applications. SIAM J. on Computing, 22(4):838–856, 1993.
[49] E. I. Nechiporuk. A boolean function. Soviet Mathematics-Doklady, 169(4):765–766, 1966.
[50] Valery A. Nepomnjaščiĭ. Rudimentary predicates and Turing calculations. Soviet Mathematics-Doklady, 11(6):1462–1465, 1970.
[51] NEU. From RAM to SAT. Available at http://www.ccs.neu.edu/home/viola/, 2012.
[52] Christos H. Papadimitriou and Mihalis Yannakakis. Optimization, approximation, and complexity classes. J. Comput. Syst. Sci., 43(3):425–440, 1991.
[53] Mihai Pǎtraşcu. Succincter. In 49th IEEE Symp. on Foundations of Computer Science (FOCS). IEEE, 2008.
[54] Wolfgang J. Paul, Nicholas Pippenger, Endre Szemer�di, and William T. Trotter. On determinism versus non-determinism and related problems (preliminary version). In IEEE Symp. on Foundations of Computer Science (FOCS), pages 429–438, 1983.
[55] Nicholas Pippenger and Michael J. Fischer. Relations among complexity measures. J. of the ACM, 26(2):361–381, 1979.
[56] Alexander Razborov. Lower bounds on the dimension of schemes of bounded depth in a complete basis containing the logical addition function. Akademiya Nauk SSSR. Matematicheskie Zametki, 41(4):598–607, 1987. English translation in Mathematical Notes of the Academy of Sci. of the USSR, 41(4):333-338, 1987.
[57] Omer Reingold. Undirected connectivity in log-space. J. of the ACM, 55(4), 2008.
[58] J. M. Robson. N by N checkers is exptime complete. SIAM J. Comput., 13(2):252–267, 1984.
[59] Rahul Santhanam. On separators, segregators and time versus space. In IEEE Conf. on Computational Complexity (CCC), pages 286–294, 2001.
[60] Walter J. Savitch. Relationships between nondeterministic and deterministic tape complexities. Journal of Computer and System Sciences, 4(2):177–192, 1970.
[61] Arnold Sch�nhage. Storage modification machines. SIAM J. Comput., 9(3):490–508, 1980.
[62] Adi Shamir. IP = PSPACE. J. of the ACM, 39(4):869–877, October 1992.
[63] Claude E. Shannon. The synthesis of two-terminal switching circuits. Bell System Tech. J., 28:59–98, 1949.
[64] Victor Shoup. New algorithms for finding irreducible polynomials over finite fields. Mathematics of Computation, 54(189):435–447, 1990.
[65] Alan Siegel. On universal classes of extremely random constant-time hash functions. SIAM J. on Computing, 33(3):505–543, 2004.
[66] Michael Sipser. A complexity theoretic approach to randomness. In ACM Symp. on the Theory of Computing (STOC), pages 330–335, 1983.
[67] Roman Smolensky. Algebraic methods in the theory of lower bounds for Boolean circuit complexity. In 19th ACM Symp. on the Theory of Computing (STOC), pages 77–82. ACM, 1987.
[68] Larry Stockmeyer and Albert R. Meyer. Cosmological lower bound on the circuit complexity of a small problem in logic. J. ACM, 49(6):753–784, 2002.
[69] Seinosuke Toda. PP is as hard as the polynomial-time hierarchy. SIAM J. on Computing, 20(5):865–877, 1991.
[70] Alan M. Turing. On computable numbers, with an application to the entscheidungsproblem. Proc. London Math. Soc., s2-42(1):230–265, 1937.
[71] Leslie G. Valiant. Graph-theoretic arguments in low-level complexity. In 6th Symposium on Mathematical Foundations of Computer Science, volume 53 of Lecture Notes in Computer Science, pages 162–176. Springer, 1977.
[72] Leslie G. Valiant and Vijay V. Vazirani. NP is as easy as detecting unique solutions. Theor. Comput. Sci., 47(3):85–93, 1986.
[73] Dieter van Melkebeek. A survey of lower bounds for satisfiability and related problems. Foundations and Trends in Theoretical Computer Science, 2(3):197–303, 2006.
[74] Dieter van Melkebeek and Ran Raz. A time lower bound for satisfiability. Theor. Comput. Sci., 348(2-3):311–320, 2005.
[75] N. V. Vinodchandran. A note on the circuit complexity of PP. Theor. Comput. Sci., 347(1-2):415–418, 2005.
[76] Emanuele Viola. Gems of theoretical computer science. Lecture notes of the class taught at Northeastern University. Available at http://www.ccs.neu.edu/home/viola/classes/gems-08/index.html, 2009.
[77] Emanuele Viola. On approximate majority and probabilistic time. Computational Complexity, 18(3):337–375, 2009.
[78] Emanuele Viola. On the power of small-depth computation. Foundations and Trends in Theoretical Computer Science, 5(1):1–72, 2009.
[79] Emanuele Viola. Reducing 3XOR to listing triangles, an exposition. Available at http://www.ccs.neu.edu/home/viola/, 2011.
[80] Emanuele Viola. Bit-probe lower bounds for succinct data structures. SIAM J. on Computing, 41(6):1593–1604, 2012.
[81] Emanuele Viola. Lower bounds for data structures with space close to maximum imply circuit lower bounds. Theory of Computing, 15:1–9, 2019. Available at http://www.ccs.neu.edu/home/viola/.
[82] Emanuele Viola. Pseudorandom bits and lower bounds for randomized turing machines. Theory of Computing, 18(10):1–12, 2022.