Random Circuit Sampling: Fourier Expansion and Statistics
Combinatorics and more 2024-04-02
Our new paper
Yosi Rinott, Tomer Shoham and I wrote a new paper on our statistical study of the data from the 2019 Google quantum supremacy experiment.
Random Circuit Sampling: Fourier Expansion and Statistics, by Gil Kalai, Yosef Rinott, and Tomer Shoham
This version is still a draft and any corrections, comments, related thoughts, and discussion are most welcome. In my view the results are quite interesting; we develop statistical tools and study data from experiments and simulations. As before, we try to discuss as much as possible the findings and possible interpretations with the authors of the Google paper other papers that we study.
Summary: We use Fourier-Walsh analysis for statistical analysis of samples coming from noisy quantum circuits. For this purpose we develop some models and statistical tools such as a Fourier-based refinement of the linear cross entropy estimator. We also develop computational methods that allow us to compute more efficiently some estimators introduced in our statistical science paper. We applied these tools to the samples from the 2019 quantum supremacy experiment, and also to simulations of noisy circuits via Google’s “Weber QVM simulator” and IBM’s “Fake Guadalupe simulator”, and we ran a few 5-qubit experiments of our own on IBM’s quantum computers.
We compared the behavior between samples of the 2019 experiment and samples from Google’s simulator. Recently, we ran our analysis tools on samples coming from the Harvard-MIT-QuEra 2024 paper on neutral atom logical circuits.
What we do in the paper and some of our findings
A) We define and study a 2-parameter noise model that seems appropriate for NISQ experiments. Our model is more general than Google’s noise model and it captures the effect of readout errors and (to some extent) of gate errors. We refer to one of the estimated parameters as the “effective readout error”: It accounts for the average readout error and additional similar mathematical effect that comes from gate errors.
B) We refine the XEB type fidelity estimators to an estimator 

C) We use the fast Fourier-Walsh algorithm to efficiently compute estimators (mainly those related to readout errors) from our statistical science paper.
D) We analyze data using our Fourier methods (and tools from our stat, sci. paper) that comes from:
- The Google 2019 quantum supremacy paper
- Noisy simulations using both Google’s and IBM’s simulators
- Five-qubit circuits that we ran on IBM computers “Jakarta” and “Nairobi”.
- (Very new) Data from 12-qubit logical circuits from the 2024 paper by Bluvstein et al.
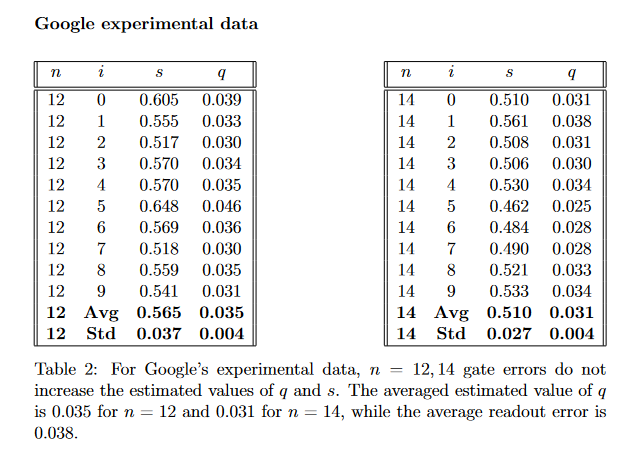
E) One of our findings is that the effect of gate errors towards larger effective readout errors is witnessed in data coming from Google’s simulator (and other simulators) but not in the samples of the Google quantum supremacy experiment.
F) (preliminary) The Fourier behavior of the samples for 12-qubit logical circuits (via the [8,3,2]-color code) from the 2024 paper by Bluvstein et al. is highly stable unlike the behavior for samples coming from other sources. (We discussed this paper in this earlier post.)
Once we get more data about the Harvard/MIT/QuEra neutral atoms logical circuits experiment from the researchers we will apply our programs to the data (and perhaps develop new tools to study it).
Let me mention Ohad Lev who was a member of our team and did a great job in running simulations and real quantum circuits.
Some tables and Figures
In the following tables the two parameters 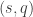

Here are some nice Figures. In the top figures we see the contribution of degree-


Relations to my earlier research directions
Here are five issues that I studied over the years, and I am quite happy to see that the new paper has some connections to all five. (The main connection is with the third item which is emphasized.)
1) Fourier analysis of Boolean functions, the noise operator, and the notions of noise sensitivity and noise stability.
2) Applying Fourier analysis to the study of noisy intermediate scale (NISQ) quantum computers. (In my work, this was connected to quantum computers skepticism.) This reflects my work on quantum computing from 2013.
3) Studying statistical aspects of samples coming from NISQ computers and especially data coming from the Google 2019 “quantum supremacy” experiment. Much of this study is around the XEB estimator for fidelity. This reflects my work with Yosi Rinott and Tomer Shoham since December 2019 or so.
4) Scrutinizing the Google 2019 “quantum supremacy” experiment: raising concerns about the quality and the reliability of the data and of the experiment. This reflects another aspect of my work with Yosi Rinott and Tomer Shoham.
5) Studying correlation between errors as a potential obstacle for quantum computation. This reflects my work on quantum computing between 2005-2013.
I find the third item more pleasant than the fourth item. Raising concerns about a scientific paper by colleagues is a delicate matter and it gives me personally a feeling of being some sort of a detective. (I had some experience in that in the late 90s.) Of course, the primary responsibility of scrutinizing scientific claims lies at the hands of the researchers themselves.
The Fourier connection (items 1 and 2)
The Fourier connection is quite close to my heart. It is related to old papers of mine from the late 1980s and 1990s. The 1999 Benjamini-Kalai-Schramm paper on noise stability and noise sensitivity, the 1988 Kahn-Kalai-Linial paper on influences and quite a few other papers. The Fourier connection is also related to more recent papers about quantum computing starting with a 2014 paper with Guy Kindler. The Fourier connection in the quantum context is related to works of people on our mailing list regarding the Google experiment: a 2017 paper by Boixo, Smelyanskiy, and Neven; a 2018 paper by Gao and Duan; a 2021 paper by Gao, Kalinowski, Chou, Lukin, Barak, and Choi; and a 2023 paper by Aharonov, Gao, Landau, Liu, and Vazirani. Let me mention that similar Fourier-type decomposition in the context of statistics were studied by Yosi Rinott in the early 1980s. Also, Ashley Montanaro, and Tobias J. Osborne (and perhaps others) extended ABS (analysis of Boolean function) to the quantum setting in a 2008 paper.
Some technical details
A) Fourier analysis of Boolean functions and the noise operator.
Recall that every real function 


![\displaystyle f(x)=\sum \{\widehat f(S)W_S(x):S \subset [n]\},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f%28x%29%3D%5Csum+%5C%7B%5Cwidehat+f%28S%29W_S%28x%29%3AS+%5Csubset+%5Bn%5D%5C%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
is a representation of 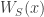

![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
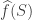

A basic insight in the analysis of Boolean functions is the relevance of the noise operator 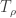

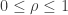
![\displaystyle T_{\rho}(f) = \sum \{\rho^{|S|} \widehat f(S)W_S(x):S \subset [n]\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+T_%7B%5Crho%7D%28f%29+%3D+%5Csum+%5C%7B%5Crho%5E%7B%7CS%7C%7D+%5Cwidehat+f%28S%29W_S%28x%29%3AS+%5Csubset+%5Bn%5D%5C%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
Readout errors, namely, reading with probability $q$ a qubit as “0″ when it is in fact “1″ and vice versa, directly correspond to the noise operator 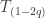
B) Our basic 2-parameter noise model
When the probability distribution described by a random circuit 
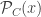
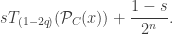
One ingredient of our analysis is finding the best fit to this model.
Here are three noise models:
1) GNM – The Google noise model from the Google 2019 quantum supremacy paper. For this model 


2) RNM – The (symmetric) readout noise model that we considered in our Statistical Science paper. For this model 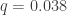

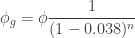
(Note that both the Google noise model where every error takes you to a random bitstring and our symmetric readout model where every gate error takes you to a random bitstring leads to correlated errors that are quite “unfriendly” to error correction schemes.)
3) WNM – the noise model described by Google’s Weber-QVM simulator which is Google’s most accurate publicly available full noise model for the Sycamore quantum computer. We cannot analyze analytically the effective readout error for WNM but simulations show that it leads to an effective readout error which is substantially larger than the “physical” readout errors.
C) Fourier refinement of the (normalized) XEB fidelity estimators
We define a refinement 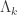
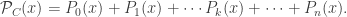
The estimator 
D) Comparing the Google 2019 experimental data to simulations
We used maximum likelihood estimator (MLE) for the pair
One of our findings is (roughly) that the behavior of Fourier-Walsh coefficients for the data from the 2019 supremacy experiment agrees with a model of noise where every gate-error sends you to random uniform bitstrings (RNM), and does not agree with the behavior of WNM based on the Google’s simulator where gate errors have similar (but smaller) additional effect on the Fourier-Walsh coefficients to that of readout errors. An additional effect of gate errors of the kind observed in simulations is seen for the IBM simulators “Fake Guadalope” and our 5-qubit quantum computer experiments on the IBM quantum computers. The behavior of the simulators appears to be consistent with the results of the papers of Gao et al. and Aharonov et al.
E) The interpretation of the findings: Do they raise additional concerns (or support earlier concerns) about the Google 2019 experiment?
The finding regarding noise modeling of the Sycamore quantum computer may be a genuine interesting finding about NISQ devices, or specific finding about the Sycamore quantum computer, and it may be an artifact of some methodological problem with the 2019 experiment of the kind suggested by our previous papers.
As I said, at this stage, we try to discuss as much as possible the findings and possible interpretations with the authors of the original papers, especially with the Google team (mainly with Sergio Boixo and John Martinis), with whom (and a few others) we had a useful email discussion from late 2019 to May 2023. I look forward to further discussion in the context of our new paper.
We also had useful correspondence with Seth Merkel who was an author of the IBM 6-qubit experiment and with Dolev Bluvshtein from the very recent Harvard/MIT/QuEra logical circuit experiment (and the first author of that paper).
Comparing Google and IBM
This is sort of an interesting side issue. As far as we can see, the difference between Google’s empirical assertions from 2019 for random circuits with 12–53 qubits and the current situation with random circuit sampling on IBM quantum computers is quite substantial. While IBM offered online quantum computers in the range between 7 and 133 qubits, we are not aware of random circuit experiments on those IBM computers with more than seven qubits. We ran some experiments with 5 qubits (on 7-qubit quantum computers “Jakarta” and “Nairobi”) and there is a 2021 paper by Kim et al. describing an experiment with 6 qubits. Seth Merkel helped us setting our 5-qubit experiment and ran by himself a seven-qubit experiment on an IBM QC. We are not aware of IBM random circuit sampling experiments with more qubits, and we do not know if running on the actual IBM Guadalupe quantum computer (or some other IBM quantum computer) 12-qubit circuits similar to those we simulated on the “Fake Guadalupe” simulator can lead to samples of fair quality or even to quality similar to the simulations. We note that recently, IBM changed their policy making it harder for researchers (and students) to experiment on their quantum computers.
The situation is not clear to me: on the one hand it looks that IBM is more advanced than other companies. For example, IBM is the only company having a high quality fabrication facility for quantum computers and people I talked to think that this makes a notable difference for higher quality quantum computers. On the other hand, it seems to me that IBM did not (and perhaps cannot) present a 12-qubit random circuit with a good quality.
If any reader has some more information on running random circuits on IBM quantum computers (or other quantum computers) we will be happy to learn about them.
Coefficient of variation
Recall that the coefficient of variation (CV) is the standard deviation divided by the average. It is a standardized measure of dispersion of a probability distribution. Another interesting finding from our paper is that the CV of the estimated parameters 
We wrote three earlier papers. Here are links to all four:
- Y. Rinott, T. Shoham, and G. Kalai, Statistical Aspects of the Quantum Supremacy Demonstration, Statistical Science (2022)
- G. Kalai, Y. Rinott and T. Shoham, Google’s 2019 “Quantum Supremacy” Claims: Data, Documentation, & Discussion (see this post).
- G. Kalai, Y. Rinott and T. Shoham, Questions and Concerns About Google’s Quantum Supremacy Claim (see this post).
- G. Kalai, Y. Rinott and T. Shoham, Random circuit sampling: Fourier expansion and statistics.