To cheer you up in difficult times 32, Annika Heckel’s guest post: How does the Chromatic Number of a Random Graph Vary?
Combinatorics and more 2021-10-02
This is a guest post kindly written by Annika Heckel. We first reported about Annika Heckel’s breakthrough in this post. A pdf version of this post can be found here.
Pick an 
The chromatic number of a random graph is a random variable, so what we are really asking is: Is this random variable essentially deterministic? That is, is the weight of the distribution concentrated on one value, or on just a few values which are close together?
Until recently we did not know whether or not this is the case. In this blog post I’ll describe a new result showing that, at least for infinitely many 
Random graphs
A uniform 



Results about
The typical value
On (i), we have the well-known 1987 result of Bollobás who showed that, with high probability (whp), 

(I am writing out this result because it will become important when talking about question (ii) later.)
Upper concentration bounds
So how about the width of the distribution of
Of course (1) is already a weak concentration type result, giving an explicit such interval of length 
The starting point for question (ii) is the classic 1987 result of Shamir and Spencer, who showed that for any function 



The opposite question
In view of strong results showing that the chromatic number is sharply concentrated, in the late 1980s Bollobas raised the following question (later popularised by him and Erdos): Can we find any examples where χ(Gn,p) is not very sharply concentrated? This is trivially true for p = 1 − 1/(10n) (as noted by Alonand Krivelevich), but how about non-trivial examples, and what about the mostnatural special case, p = 1/2?
This question remained open for quite some time, for a simple reason: whilewe have a number of standard tools to prove upper bounds on the concentrationof a random variable (for example the martingale concentration argument ofShamir and Spencer), we have few ways of giving lower concentration bounds.(Unless we can work out the entire approximate distribution, for example byproving asymptotic normality.)A lower bound for concentrationI will sketch the main ideas needed for the following result:
Theorem 1 (H. 2019; H., Riordan 2021). Let ε > 0, and let ![{[s_n, t_n]}](https://s0.wp.com/latex.php?latex=%7B%5Bs_n%2C+t_n%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002)
![{\chi(G_{n, 1/2}) \in [s_n, t_n]}](https://s0.wp.com/latex.php?latex=%7B%5Cchi%28G_%7Bn%2C+1%2F2%7D%29+%5Cin+%5Bs_n%2C+t_n%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002)
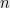

Of course we can also replace 


A word of caution: The theorem only says that there are some 
Basic proof strategy
The proof needs two ingredients:(1) A (weak) concentration type result
A result that says that, whp, 





(2) A coupling result
A coupling that shows that, for 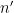

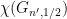
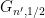


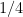

Now suppose ![{[s_n, t_n]}](https://s0.wp.com/latex.php?latex=%7B%5Bs_n%2C+t_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



If all intervals were short, then as we increase
Working out the numbers, under certain reasonable conditions there is an interval of length about 


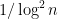

Independence number and large independent sets
So what’s the function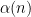 ? This turns out to be the independence number of
? This turns out to be the independence number of  , that is, the size of the largest independent vertex set. Matula and independently Bollobás and Erdős proved that the independence number of behaves almost deterministically: for most , whp it takes an explicitly known deterministic value
, that is, the size of the largest independent vertex set. Matula and independently Bollobás and Erdős proved that the independence number of behaves almost deterministically: for most , whp it takes an explicitly known deterministic value  .
. What does this have to do with 
We call an independent set of size 
Let 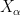


![{\theta = \theta(n) \in [o(1),1+o(1)]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%3D+%5Ctheta%28n%29+%5Cin+%5Bo%281%29%2C1%2Bo%281%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

The weak concentration result
Luckily we already have a suitable estimate for in (1). Writing for this estimate, then for most ,
So what is the effect of having one extra 

colours. So 
The coupling
We construct the coupling in the following way: take vertices (we will pick later). Choose vertex sets of size uniformly at random and make them independent sets, and then include every edge outside these -sets independently with probability .
vertices (we will pick later). Choose vertex sets of size uniformly at random and make them independent sets, and then include every edge outside these -sets independently with probability .
The inner graph 
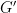

This is because any colouring of
The trouble is that
So we let 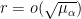

Tying it all together
The two ingredients above can be combined to show that for every, there is some nearby 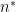 with concentration interval length
with concentration interval length  , with
, with  . If we pick so that
. If we pick so that  is close to , Theorem~1 follows.
is close to , Theorem~1 follows. How close to Shamir and Spencer’s upper bound 
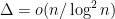
Konstantinos Panagiotou and I have been working on an improved estimate for
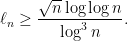
The best upper concentration bound for 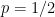

Which of these is closer to the truth? We conjecture that, for the worst case
The Zigzag conjecture
Let be the standard deviation of . We already gave a heuristic argument that
be the standard deviation of . We already gave a heuristic argument that  , coming from fluctuations in the number of -sets.
, coming from fluctuations in the number of -sets. There is another conjectured lower bound coming from fluctuations in 
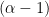
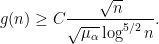
The Zigzag conjecture, made recently by Bollobás, Heckel, Morris, Panagiotou, Riordan and Smith, states that at least for most 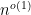
Define 

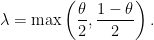
Then, if


It is not hard to show that the function 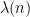

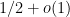
There’s a detailed heuristic explanation of the conjecture in the paper. We also think that we have a pretty good idea of the behaviour of 
