The Space of Physical Frameworks (Part 4)
Azimuth 2024-09-16
In Part 1, I explained my hopes that classical statistical mechanics reduces to thermodynamics in the limit where Boltzmann’s constant 
In Part 3, I showed how a Legendre transform can arise as a limit of something like a Laplace transform.
Today I’ll put all the puzzle pieces together. I’ll explain exactly what I mean by ‘classical statistical mechanics’, and how negative free entropy is defined in this framework. Its definition involves a Laplace transform. Finally, using the result from Part 3, I’ll show that as 
Thermodynamics versus statistical mechanics
In a certain important approach to thermodynamics, called classical thermodynamics, we only study relations between the ‘macroscopic observables’ of a system. These are the things you can measure at human-sized distance scales, like the energy, temperature, volume and pressure of a canister of gas. We don’t think about individual atoms and molecules! We say the values of all the macroscopic observables specify the system’s macrostate. So when I formalized thermodynamics using ‘thermostatic systems’ in Part 2, the ‘space of states’ 
I focused on the simple case where the macrostate is completely characterized by a single macroscopic observable called its energy 

In classical statistical mechanics we go further and consider the set 

To connect thermodynamics to classical statistical mechanics, we need to connect macrostates to microstates. The relation is that each macrostate is a probability distribution of microstates: a probability distribution that maximizes entropy subject to constraints on the expected values of macroscopic observables.
To see in detail how this works, let’s focus on the simple case where our only macroscopic observable is energy.
Classical statistical mechanical systems
Definition. A classical statistical mechanical system is a measure space 

We call 
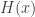
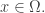
It gets tiring to say ‘classical statistical mechanical system’, so I’ll abbreviate this as classical stat mech system.
When we macroscopically measure the energy of a classical stat mech system to be 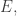


with

The expected energy in this probability distribution is defined to be

So what I’m saying is that 
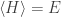
But lots of probability distributions have 

Here
Now, there may not exist a probability distribution 


Here 
The normalizing factor in the formula above is called the partition function

and it turns out to be important in its own right. The integral may not always converge, but when it does not we’ll just say it equals 
![Z_k \colon [0,\infty) \to [0,\infty]](https://s0.wp.com/latex.php?latex=Z_k+%5Ccolon+%5B0%2C%5Cinfty%29+%5Cto+%5B0%2C%5Cinfty%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
One reason the partition function is important is that

where 



Let’s call the negative free entropy 

I’ve already discussed negative free entropy in Part 2, but that was for thermostatic systems, and it was defined using a Legendre transform. This new version of negative free entropy applies to classical stat mech systems, and we’ll see it’s defined using a Laplace transform. But they’re related: we’ll see the limit of the new one as 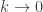
The limit as
To compute the limit of the negative free entropy 
First, given a classical stat mech system with measure space 


be the measure of the set of microstates with energy 



The reason I care about this measure 

Very often the measure

for some locally integrable function 

Physicists call 
![[E, E + \Delta E]](https://s0.wp.com/latex.php?latex=%5BE%2C+E+%2B+%5CDelta+E%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Before moving on, a word about dimensional analysis. I’m doing physics, so my quantities have dimensions. In particular, 


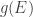
This matters because right now I want to take the logarithm of 

With that said, now let’s introduce the so-called microcanonical entropy, often called the Boltzmann entropy:

Here we are taking Boltzmann’s old idea of entropy as
In terms of the microcanonical entropy, we have

Combining this with our earlier formula

we get this formula for the partition function:

Now things are getting interesting!
First, the quantity 

Second, we instantly get a beautiful formula for the negative free entropy of a classical stat mech system:

Using this we can show the following cool fact:
Main Result. Suppose 



The quantity at right deserves to be called the microcanonical negative free entropy. So, when the hypotheses hold,
As
Here I’ve left off the word ‘negative’ twice, which is fine. But this sentence still sounds like a mouthful. Don’t feel bad if you find it confusing. But it could be the result we need to see how classical statistical mechanics approaches classical thermodynamics as 
But today I’ll just prove the main result and quit. I figure it’s good to get the math done before talking more about what it means.
Proof of the main result
Suppose all the hypotheses of the main result hold. Spelling out the definition of the negative free entropy


You’ll notice that the left hand side involves the energy width 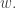



So, we are allowed to let

Next, we need a theorem from Part 3. My argument for that theorem was not a full mathematical proof — I explained the hole I still need to fill — so I cautiously called it an ‘almost proved theorem’. Here it is:
Almost Proved Theorem. Suppose that 




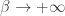

Now let’s use this to prove our main result! To do this, take

Then we get


and this is exactly what we want… in the case where 