Polarities (Part 1)
Azimuth 2024-11-03
This is a progress report on some joint work with Xiaoyan Li, Nathaniel Osgood and Evan Patterson. Together with collaborators we have been developing software for ‘system dynamics’ modelling, and applying it to epidemiology—though it has many other uses. We’ve written two papers about it, and given plenty of talks:
• Software for compositional modeling.
But the software keeps growing—so it’s time to write another paper or two! First we’re writing one aimed at applied category theorists, where we explain the math in detail, and don’t pull any punches. One small part of this paper involves the concept of ‘polarities’. Let me explain those now.
Causal loop diagrams
In the tradition of system dynamics we model systems at various levels of detail using at least three kinds of diagrams. The most detail is provided by stock and flow diagrams: from such a diagram we can recover a system of first-order ordinary differential equations describing how quantities called ‘stocks’ change due to ‘flows’ between these stocks. A ‘system structure diagram’ is like a stock and flow diagram without the functions describing how flows are functions of stocks. The least detail is provided by a causal loop diagram, and this is what I want to talk about now.
Here is a causal loop diagram drawn by Six Sigma, a consulting company that aims to help you find problems in your organization and fix them:

Mathematically a causal loop diagram is a graph whose edges are labeled by signs, + and -. A positive edge

means that increasing 
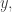


means that increasing
As the name suggests, the main use of causal loop diagrams is to detect feedback loops. Suppose we go around a loop of edges, multiplying the signs as we go, following the usual rules:




If the result is a + sign, then we call this loop a positive feedback loop. If the result is a – sign, we call this loop a negative feedback loop.
For example, here is a positive feedback loop:

Increasing the number of employees available to work increases productivity, which decreases the number of managers doing employees’ duties, which increases the quality of supervision, which decreases the employees who are late, which increases the number of employees available to work!
Can you spot a negative feedback loop in this diagram?
Polarities
So far all this is very simple—and indeed that’s part of the point: causal loop diagrams are so easy to understand that you can walk into a business, talk to them about their problems, and start drawing diagrams that shed light on the feedback loops that they’re encountering.
But causal loop diagrams get a bit more interesting when we replace signs by more general ‘polarities’. Mathematically, polarities can be elements of any monoid: a set with an associative multiplication and a unit element. The monoid of signs, 

For example we can take our set of polarities to be

where 0 means ‘indeterminate’. Now this edge:

means that increasing the quantity
Mathematicians will instantly recognize that this multiplication rule makes the set 

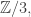
There are other interesting monoids we can use as polarities. But instead of listing a bunch, let me explain a simple thing what we do wit causal loop diagrams. It’s something we’ve already been talking about.
From causal loop diagrams to categories
Let’s be a bit more formal. A graph with edges 


We say 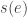
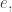
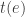
Given any set 


But when the set 

a causal loop diagram over
What can we do with a causal loop diagram over 

A morphism 



defined using multiplication in the monoid
For example, suppose 
This means it’s a negative feedback loop.
But what’s really going on here? We have a map 

So, this map is really a functor from 



Note, we don’t need to say what our functor

does to objects, since 
This viewpoint is quite nice. For example, the ‘free’ functor
has a right adjoint

sending any category to its underlying graph. Using the properties of adjoints, our functor
gives a map of graphs
Here 


It’s just our original labeling 
Lemma. Given a monoid
since 

There’s a lot more to say, but I’ll stop here for now and continue later. I’ve decided people just don’t read long blog articles.