The Category Theory Behind UMAP
Azimuth 2020-02-09
An interesting situation has arisen. Some people working on applied category theory have been seeking a ‘killer app’: that is, an application of category theory to practical tasks that would be so compelling it would force the world to admit categories are useful. Meanwhile, the UMAP algorithm, based to some extent on category theory, has become very important in genomics:
• Leland McInnes, John Healy, James Melville, UMAP: uniform manifold approximation and projection for dimension reduction.
But while practitioners have embraced the algorithm, they’re still puzzled by its category-theoretic underpinnings, which are discussed in Section 2 of the paper. (You can read the remaining sections, which describe the algorithm quite concretely, without understanding Section 2.)
I first heard of this situation on Twitter when James Nichols wrote:
Wow! My first sighting of applied category theory: the UMAP algorithm. I’m a category novice, but the resulting adjacency-graph algorithm is v simple, so surely the theory boils down to reasonably simple arguments in topology/Riemannian geometry?
Do any of you prolific ACT tweeters know much about UMAP? I understand the gist of the linked paper, but not say why we need category theory to define this “fuzzy topology” concept, as opposed to some other analytic defn.
Junhyong Kim added:
What was gained by CT for UMAP? (honest question, not trying to be snarky)
Leland McInnes, one of the inventors of UMAP, responded:
It is my math background, how I think about the problem, and how the algorithm was derived. It wasn’t something that was added, but rather something that was always there—for me at least. In that sense what was gained was the algorithm.
I don’t really understand UMAP; for a good introduction to it see the original paper above and also this:
• Nikolay Oskolkov, How Exactly UMAP Works—and Why Exactly It Is Better Than tSNE, 3 October 2019.
tSNE is an older algorithm for taking clouds of data points in high dimensions and mapping them down to fewer dimensions so we can understand what’s going on. From the viewpoint of those working on genomics, the main good thing about UMAP is that it solves a bunch of problems that plagued tSNE. Oskolkov explains what these problems are and how UMAP deals with them. But he also alludes to the funny disconnect between these practicalities and the underlying theory:
My first impression when I heard about UMAP was that this was a completely novel and interesting dimension reduction technique which is based on solid mathematical principles and hence very different from tSNE which is a pure Machine Learning semi-empirical algorithm. My colleagues from Biology told me that the original UMAP paper was “too mathematical”, and looking at the Section 2 of the paper I was very happy to see strict and accurate mathematics finally coming to Life and Data Science. However, reading the UMAP docs and watching Leland McInnes talk at SciPy 2018, I got puzzled and felt like UMAP was another neighbor graph technique which is so similar to tSNE that I was struggling to understand how exactly UMAP is different from tSNE.
He then goes on and attempts to explain exactly why UMAP does so much better than tSNE. None of his explanation mentions category theory.
Since I don’t really understand UMAP or why it does better than tSNE, I can’t add anything to this discussion. In particular, I can’t say how much the category theory really helps. All I can do is explain a bit of the category theory. I’ll do that now, very briefly, just as a way to get a conversation going. I will try to avoid category-theoretic jargon as much as possible—not because I don’t like it or consider it unimportant, but because that jargon is precisely what’s stopping certain people from understanding Section 2.
I think it all starts with this paper by Spivak:
• David Spivak, Metric realization of fuzzy simplicial sets.
Spivak showed how to turn a ‘fuzzy simplicial set’ into an ‘uber-metric space’ and vice versa. What are these things?
An ‘uber-metric space’ is very simple. It’s a slight generalization of a metric space that relaxes the usual definition in just two ways: it lets distances be infinite, and it lets distinct points have distance zero from each other. This sort of generalization can be very useful. I could talk about it a lot, but I won’t.
A fuzzy simplicial set is a generalization of a simplicial set.
A simplicial set starts out as a set of vertices (or 0-simplices), a set of edges (or 1-simplices), a set of triangles (or 2-simplices), a set of tetrahedra (or 3-simplices), and so on: in short, a set of n-simplices for each n. But there’s more to it. Most importantly, each n-simplex has a bunch of faces, which are lower-dimensional simplices.
I won’t give the whole definition. To a first approximation you can visualize a simplicial set as being like this:
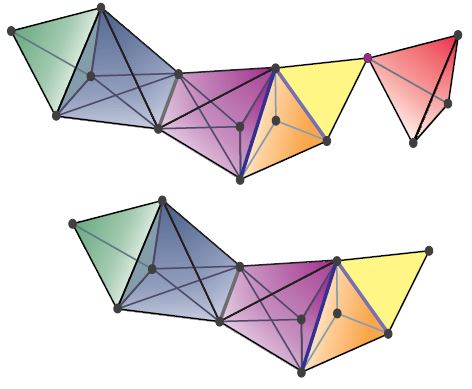
But of course it doesn’t have to stop at dimension 3—and more subtly, you can have things like two different triangles that have exactly the same edges.
In a ‘fuzzy’ simplicial set, instead of a set of n-simplices for each n, we have a fuzzy set of them. But what’s a fuzzy set?
Fuzzy set theory is good for studying collections where membership is somewhat vaguely defined. Like a set, a fuzzy set has elements, but each element has a ‘degree of membership’ that is a number 0 < x ≤ 1. (If its degree of membership were zero, it wouldn't be an element!)
A map f: X → Y between fuzzy sets is an ordinary function, but obeying this condition: it can only send an element x ∈ X to an element f(x) ∈ Y whose degree of membership is greater than or equal to that of x. In other words, we don't want functions that send things to things with a lower degree of membership.
Why? Well, if I'm quite sure something is a dog, and every dog has a nose, then I'm must be at least equally sure that this dog has a nose! (If you disagree with this, then you can make up some other concept of fuzzy set. There are a number of such concepts, and I'm just describing one.)
So, a fuzzy simplicial set will have a set of n-simplices for each n, with each n-simplex having a degree of membership… but the degree of membership of its faces can't be less than its own degree of membership.
This is not the precise definition of fuzzy simplicial set, because I'm leaving out some distracting nuances. But you can get the precise definition by taking a nuts-and-bolts definition of simplicial set, like Definition 3.2 here:
• Greg Friedman, An elementary illustrated introduction to simplicial sets.
and replacing all the sets by fuzzy sets, and all the maps by maps between fuzzy sets.
If you like visualizing things, you can visualize a fuzzy simplicial set as an ordinary simplicial set, as in the picture above, but where an n-simplex is shaded darker if its degree of membership is higher. An n-simplex can’t be shaded darker than any of its faces.
How can you turn a fuzzy simplicial set into an uber-metric space? And how can you turn an uber-metric space into a fuzzy simplicial set?
Spivak focuses on the first question, because the answer is simpler, and it determines the answer to the second using some nice math.
The answer to the first question goes like this. Say you have a fuzzy simplicial set. For each n-simplex whose degree of membership equals 
 : t_0 + \cdots + t_n = - \log a \} \subseteq \mathbb{R}^{n+1}")
This is really just an ordinary metric space: an n-simplex that’s a subspace of Euclidean (n+1)-dimensional space with its usual Euclidean distance function. Then you glue together all these uber-metric spaces, one for each simplex in your fuzzy simplical set, to get a big fat uber-metric space.
This process is called ‘realization’. The key here is that if an n-simplex has a high degree of membership, it gets ‘realized’ as a metric space shaped like a small n-simplex. I believe the basic intuition is that an n-simplex with a high degree of membership describes an (n+1)-tuple of things—its vertices—that are close to each other.
In theory, I should try to describe the reverse process that turns an uber-metric space into a fuzzy simplicial set. If I did, I believe we would see that whenever an (n+1)-tuple of things—that is, points of our uber-metric space—are close, they give an n-simplex with a high degree of membership.
If so, then both uber-metric spaces and fuzzy simplicial sets are just ways of talking about which collections of data points are close, and we can translate back and forth between these descriptions.
But I’d need to think about this a bit more to do a good job of going further, and reading the UMAP paper a bit more I’m beginning to suspect that’s not the main thing that practitioners need to know. I’m beginning to think the most important thing is to get a feeling for fuzzy simplicial sets! I hope I’ve helped a bit in that direction.
(I should admit that McInnes, Healy and Melville tweak Spivak’s formalism a bit. They call Spivak’s uber-metric spaces ‘extended pseudo-metric-spaces’, but they focus on a special kind, which they call ‘finite’. Unfortunately, I can’t find where they define this term. They also only consider a special sort of fuzzy simplicial set, which they call ‘bounded’, but I can’t find the definition of this term either! Without knowing these definitions, I can’t comment on how these tweaks change things.)