A computation-outsourced discussion of zero density theorems for the Riemann zeta function
What's new 2024-07-07
Many modern mathematical proofs are a combination of conceptual arguments and technical calculations. There is something of a tradeoff between the two: one can add more conceptual arguments to try to reduce the technical computations, or vice versa. (Among other things, this leads to a Berkson paradox-like phenomenon in which a negative correlation can be observed between the two aspects of a proof; see this recent Mastodon post of mine for more discussion.)
In a recent article, Heather Macbeth argues that the preferred balance between conceptual and computational arguments is quite different for a computer-assisted proof than it is for a purely human-readable proof. In the latter, there is a strong incentive to minimize the amount of calculation to the point where it can be checked by hand, even if this requires a certain amount of ad hoc rearrangement of cases, unmotivated parameter selection, or otherwise non-conceptual additions to the arguments in order to reduce the calculation. But in the former, once one is willing to outsource any tedious verification or optimization task to a computer, the incentives are reversed: freed from the need to arrange the argument to reduce the amount of calculation, one can now describe an argument by listing the main ingredients and then letting the computer figure out a suitable way to combine them to give the stated result. The two approaches can thus be viewed as complementary ways to describe a result, with neither necessarily being superior to the other.
In this post, I would like to illustrate this computation-outsourced approach with the topic of zero-density theorems for the Riemann zeta function, in which all computer verifiable calculations (as well as other routine but tedious arguments) are performed “off-stage”, with the intent of focusing only on the conceptual inputs to these theorems.
Zero-density theorems concern upper bounds for the quantity 




 , the more control one has on the complicated term
, the more control one has on the complicated term  on the right-hand side.
on the right-hand side.Clearly 

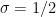 case, while the prime number theorem tells us that
case, while the prime number theorem tells us that  vanishes if
vanishes if  for some small absolute constant
for some small absolute constant  , and the Riemann hypothesis is equivalent to the assertion that
, and the Riemann hypothesis is equivalent to the assertion that  for all
for all  .
.Experience has shown that the most important quantity to control here is the exponent 

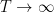 . Thus, for instance,
. Thus, for instance, 
 , and
, and  is a non-decreasing function of , so we obtain the trivial “von Mangoldt” zero density theorem
is a non-decreasing function of , so we obtain the trivial “von Mangoldt” zero density theorem 
 of
of  , which has to be at least
, which has to be at least  thanks to (3). The density hypothesis asserts that the maximum is in fact exactly , or equivalently that
thanks to (3). The density hypothesis asserts that the maximum is in fact exactly , or equivalently that  . This is of course implied by the Riemann hypothesis (which clearly implies that
. This is of course implied by the Riemann hypothesis (which clearly implies that  for all ), but is a more tractable hypothesis to work with; for instance, the hypothesis is already known to hold for
for all ), but is a more tractable hypothesis to work with; for instance, the hypothesis is already known to hold for  by the work of Bourgain (building upon many previous authors). The quantity
by the work of Bourgain (building upon many previous authors). The quantity  directly impacts our understanding of the prime number theorem in short intervals; indeed, it is not difficult using (1) (as well as the Vinogradov-Korobov zero-free region) to establish a short interval prime number theorem
directly impacts our understanding of the prime number theorem in short intervals; indeed, it is not difficult using (1) (as well as the Vinogradov-Korobov zero-free region) to establish a short interval prime number theorem 
 if
if  is a fixed exponent, or for almost all if
is a fixed exponent, or for almost all if  is a fixed exponent. Until recently, the best upper bound for was
is a fixed exponent. Until recently, the best upper bound for was  , thanks to a 1972 result of Huxley; but this was recently lowered to
, thanks to a 1972 result of Huxley; but this was recently lowered to  in a breakthrough work of Guth and Maynard.
in a breakthrough work of Guth and Maynard.In between the papers of Huxley and Guth-Maynard are dozens of additional improvements on

(For an explanation of what is going on under the assumption of the Lindelöf hypothesis, see below the fold.) This plot represents the combined effort of nearly a dozen papers, each one of which claims one or more components of the depicted piecewise smooth curve, and is written in the “human-readable” style mentioned above, where the argument is arranged to reduce the amount of tedious computation to human-verifiable levels, even if this comes the cost of obscuring the conceptual ideas. (For an animation of how this bound improved over time, see here.) Below the fold, I will try to describe (in sketch form) some of the standard ingredients that go into these papers, in particular the routine reduction of deriving zero density estimates from large value theorems for Dirichlet series. We will not attempt to rewrite the entire literature of zero-density estimates in this fashion, but focus on some illustrative special cases.
— 1. Zero detecting polynomials —
As we are willing to lose powers of 
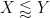




The Riemann-von Mangoldt formula implies that any unit square in the critical strip only contains 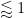




The Riemann-Siegel formula, roughly speaking, tells us that for a zero

 . One can decompose the sum here dyadically into
. One can decompose the sum here dyadically into  pieces that look like
pieces that look like 
 . The
. The 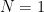 component of this sum is basically ; so if there is to be a zero at , we expect one of the other terms to balance it out, and so we should have
component of this sum is basically ; so if there is to be a zero at , we expect one of the other terms to balance it out, and so we should have 
 . In the notation of this subject, the expressions
. In the notation of this subject, the expressions  are known as zero detecting (Dirichlet) polynomials; the large values of such polynomials provide a set of candidates where zeroes can occur, and so upper bounding the large values of such polynomials will lead to zero density estimates.
are known as zero detecting (Dirichlet) polynomials; the large values of such polynomials provide a set of candidates where zeroes can occur, and so upper bounding the large values of such polynomials will lead to zero density estimates.Unfortunately, the particular choice of zero detecting polynomials described above, while simple, is not useful for applications, because the polynomials with very small values of 
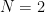
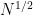









 , and another family (“Type II”) is of the form
, and another family (“Type II”) is of the form 
 and some coefficients
and some coefficients 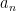 of size ; see Section 10.2 of Iwaniec-Kowalski or these lecture notes of mine, or Appendix 3 of this recent paper of Maynard and Platt for more details. It is also possible to reverse these implications and efficiently derive large values estimates from zero density theorems; see this recent paper of Matomäki and Teräväinen.
of size ; see Section 10.2 of Iwaniec-Kowalski or these lecture notes of mine, or Appendix 3 of this recent paper of Maynard and Platt for more details. It is also possible to reverse these implications and efficiently derive large values estimates from zero density theorems; see this recent paper of Matomäki and Teräväinen.One can sometimes squeeze a small amount of mileage out of optimizing the 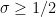




 , the number of such frquencies
, the number of such frquencies  does not exceed
does not exceed  . We define
. We define  similarly, but where the coefficients are also assumed to be identically . Then clearly
similarly, but where the coefficients are also assumed to be identically . Then clearly 
 is now basically reduced to establishing the “Type I” bound
is now basically reduced to establishing the “Type I” bound 
 , as well as the “Type II” variant
, as well as the “Type II” variant 
 .
.As we shall see, the Type II task of controlling 
Remark 1 The approximate functional equation for the Riemann zeta function morally tells us that, but we will not have much use for this symmetry since we have in some sense already incorporated it (via the Riemann-Siegel formula) into the condition
.
The standard 








 . This initially looks useless, since we are restricting to the range
. This initially looks useless, since we are restricting to the range 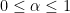 ; but there is a simple trick that allows one to greatly amplify this bound (as well as many other large values bounds). Namely, if one raises a Dirichlet series with to some natural number power
; but there is a simple trick that allows one to greatly amplify this bound (as well as many other large values bounds). Namely, if one raises a Dirichlet series with to some natural number power  , then one obtains another Dirichlet series
, then one obtains another Dirichlet series  with
with  , but now at length
, but now at length  instead of . This can be encoded in terms of the notation as the inequality
instead of . This can be encoded in terms of the notation as the inequality 
 . It would be very convenient if we could remove the restriction that be a natural number here; there is a conjecture of Montgomery in this regard, but it is out of reach of current methods (it was observed by in this paper of Bourgain that it would imply the Kakeya conjecture!). Nevertheless, the relation (12) is already quite useful. Firstly, it can easily be used to imply the Type II case (10) of the density hypothesis, and also implies the Type I case (9) as long as is of the special form
. It would be very convenient if we could remove the restriction that be a natural number here; there is a conjecture of Montgomery in this regard, but it is out of reach of current methods (it was observed by in this paper of Bourgain that it would imply the Kakeya conjecture!). Nevertheless, the relation (12) is already quite useful. Firstly, it can easily be used to imply the Type II case (10) of the density hypothesis, and also implies the Type I case (9) as long as is of the special form  for some natural number . Rather than give a human-readable proof of this routine implication, let me illustrate it instead with a graph of what the best bound one can obtain for becomes for
for some natural number . Rather than give a human-readable proof of this routine implication, let me illustrate it instead with a graph of what the best bound one can obtain for becomes for  , just using (11) and (12):
, just using (11) and (12):
Here we see that the bound for 






The method is flexible, and one can insert further bounds or hypotheses to improve the situation. For instance, the Lindelöf hypothesis asserts that 
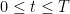
 and all fixed
and all fixed  (in fact this hypothesis is basically equivalent to this estimate). In particular, one has
(in fact this hypothesis is basically equivalent to this estimate). In particular, one has 
 and . In particular, the Type I estimate (9) now holds for all , and so the Lindeöf hypothesis implies the Density hypothesis.
and . In particular, the Type I estimate (9) now holds for all , and so the Lindeöf hypothesis implies the Density hypothesis.In fact, as observed by Hálasz and Turán in 1969, the Lindelöf hypothesis also gives good Type II control in the regime 


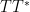
 and . This lets one go beyond the density hypothesis for
and . This lets one go beyond the density hypothesis for  and in fact obtain in this case.
and in fact obtain in this case.While we are not close to proving the full strength of (13), the theory of exponential sums gives us some relatively cood control on the left-hand side in some cases. For instance, by using van der Corput estimates on (13), Montgomery in 1969 was able to obtain an unconditional estimate which in our notation would be

 . This is already enough to give some improvements to Ingham’s bound for very large . But one can do better by a simple subdivision observation of Huxley (which was already implicitly used to prove (11)): a large values estimate on an interval of size automatically implies a large values estimate on a longer interval of size
. This is already enough to give some improvements to Ingham’s bound for very large . But one can do better by a simple subdivision observation of Huxley (which was already implicitly used to prove (11)): a large values estimate on an interval of size automatically implies a large values estimate on a longer interval of size  , simply by covering the latter interval by
, simply by covering the latter interval by  intervals. This observation can be formalized as a general inequality
intervals. This observation can be formalized as a general inequality  and
and  ; that is to say, the quantity
; that is to say, the quantity  is non-decreasing in . This leads to the Huxley large values inequality, which in our notation asserts that
is non-decreasing in . This leads to the Huxley large values inequality, which in our notation asserts that  and
and 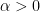 , which is superior to (11) when . If one simply adds either Montgomery’s inequality (15), or Huxley’s extension inequality (17), into the previous pool and asks the computer to optimize the bounds on as a consequence, one obtains the following graph:
, which is superior to (11) when . If one simply adds either Montgomery’s inequality (15), or Huxley’s extension inequality (17), into the previous pool and asks the computer to optimize the bounds on as a consequence, one obtains the following graph:
In particular, the density hypothesis is now established for all 


Here we immediately see that it is only the 





 ; this already shows that vanishes unless
; this already shows that vanishes unless  when
when  . If one inserts this new constraint into the pool, we recover the full strength of the Huxley bound
. If one inserts this new constraint into the pool, we recover the full strength of the Huxley bound  , and which improves upon the Ingham bound for
, and which improves upon the Ingham bound for  :
:
Remark 2 The above bounds are already sufficient to establish the inequalityfor all
, which is equivalent to the twelfth moment estimate
of Heath-Brown (albeit with a slightly worse


One can continue importing in additional large values estimates into this framework to obtain new zero density theorems, particularly for large values of

 and
and  . By subdivision (16), one also automatically obtains the same bound for
. By subdivision (16), one also automatically obtains the same bound for  as well. If one drops this estimate into the mix, one obtains the Guth-Maynard addition
as well. If one drops this estimate into the mix, one obtains the Guth-Maynard addition 
 , but only novel in the interval ):
, but only novel in the interval ):
This is not the most difficult (or novel) part of the Guth-Maynard paper – the proof of (20) occupies about 34 of the 48 pages of the paper – but it hopefully illustrates how some of the more routine portions of this type of work can be outsourced to a computer, at least if one is willing to be convinced purely by numerically produced graphs. Also, it is possible to transfer even more of the Guth-Maynard paper to this format, if one introduces an additional quantity 
The above graphs were produced by myself using some quite crude Python code (with a small amount of AI assistance, for instance via Github Copilot); the code does not actually “prove” estimates such as (19) or (21) to infinite accuracy, but rather to any specified finite accuracy, although one can at least make the bounds completely rigorous by discretizing using a mesh of rational numbers (which can be manipulated to infinite precision) and using the monotonicity properties of the various functions involved to control errors. In principle, it should be possible to create software that would work “symbolically” rather than “numerically”, and output (human-readable) proof certificates of bounds such as (21) from prior estimates such as (20) to infinite accuracy, in some formal proof verification language (e.g., Lean). Such a tool could potentially shorten the primary component of papers of this type, which would then focus on the main inputs to a standard inequality-chasing framework, rather than the routine execution of that framework which could then be deferred to an appendix or some computer-produced file. It seems that such a tool is now feasible (particularly with the potential of deploying AI tools to locate proof certificates in some tricky cases), and would be useful for many other analysis arguments involving explicit exponents than the zero-density example presented here (e.g., a version of this could have been useful to optimize constants in the recent resolution of the PFR conjecture), though perhaps the more practical workflow case for now is to use the finite-precision numerics approach to locate the correct conclusions and intermediate inequalities, and then prove those claims rigorously by hand.