There has been some spectacular progress in geometric measure theory: Hong Wang and Joshua Zahl have just released a preprint that resolves the three-dimensional case of the infamous Kakeya set conjecture! This conjecture asserts that a Kakeya set – a subset of 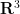 that contains a unit line segment in every direction, must have Minkowski and Hausdorff dimension equal to three. (There is also a stronger “maximal function” version of this conjecture that remains open at present, although the methods of this paper will give some non-trivial bounds on this maximal function.) It is common to discretize this conjecture in terms of small scale
that contains a unit line segment in every direction, must have Minkowski and Hausdorff dimension equal to three. (There is also a stronger “maximal function” version of this conjecture that remains open at present, although the methods of this paper will give some non-trivial bounds on this maximal function.) It is common to discretize this conjecture in terms of small scale 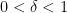 . Roughly speaking, the conjecture then asserts that if one has a family
. Roughly speaking, the conjecture then asserts that if one has a family 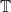 of
of  tubes of cardinality
tubes of cardinality  , and pointing in a
, and pointing in a  -separated set of directions, then the union
-separated set of directions, then the union  of these tubes should have volume
of these tubes should have volume  . Here we shall be a little vague as to what
. Here we shall be a little vague as to what 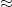 means here, but roughly one should think of this as “up to factors of the form
means here, but roughly one should think of this as “up to factors of the form  for any
for any  “; in particular this notation can absorb any logarithmic losses that might arise for instance from a dyadic pigeonholing argument. For technical reasons (including the need to invoke the aforementioned dyadic pigeonholing), one actually works with slightly smaller sets
“; in particular this notation can absorb any logarithmic losses that might arise for instance from a dyadic pigeonholing argument. For technical reasons (including the need to invoke the aforementioned dyadic pigeonholing), one actually works with slightly smaller sets  , where
, where  is a “shading” of the tubes in that assigns a large subset
is a “shading” of the tubes in that assigns a large subset 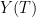 of
of  to each tube in the collection; but for this discussion we shall ignore this subtlety and pretend that we can always work with the full tubes.
to each tube in the collection; but for this discussion we shall ignore this subtlety and pretend that we can always work with the full tubes.
Previous results in this area tended to center around lower bounds of the form

for various intermediate dimensions

, that one would like to make as large as possible. For instance, just from considering a single tube in this collection, one can easily establish
(1) with
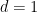
. By just using the fact that two lines in
intersect in a point (or more precisely, a more quantitative estimate on the volume between the intersection of two
tubes, based on the angle of intersection), combined with a now classical

-based argument of Córdoba, one can obtain
(1) with
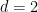
(and this type of argument also resolves the Kakeya conjecture in two dimensions). In 1995, building on earlier work by Bourgain,
Wolff famously obtained (1) with

using what is now known as the “Wolff hairbrush argument”, based on considering the size of a “hairbrush” – the union of all the tubes that pass through a single tube (the hairbrush “stem”) in the collection.
In their new paper, Wang and Zahl established (1) for  . The proof is lengthy (127 pages!), and relies crucially on their previous paper establishing a key “sticky” case of the conjecture. Here, I thought I would try to summarize the high level strategy of proof, omitting many details and also oversimplifying the argument at various places for sake of exposition. The argument does use many ideas from previous literature, including some from my own papers with co-authors; but the case analysis and iterative schemes required are remarkably sophisticated and delicate, with multiple new ideas needed to close the full argument.
. The proof is lengthy (127 pages!), and relies crucially on their previous paper establishing a key “sticky” case of the conjecture. Here, I thought I would try to summarize the high level strategy of proof, omitting many details and also oversimplifying the argument at various places for sake of exposition. The argument does use many ideas from previous literature, including some from my own papers with co-authors; but the case analysis and iterative schemes required are remarkably sophisticated and delicate, with multiple new ideas needed to close the full argument.
A natural strategy to prove (1) would be to try to induct on  : if we let
: if we let 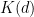 represent the assertion that (1) holds for all configurations of tubes of dimensions , with -separated directions, we could try to prove some implication of the form
represent the assertion that (1) holds for all configurations of tubes of dimensions , with -separated directions, we could try to prove some implication of the form  for all , where
for all , where 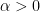 is some small positive quantity depending on . Iterating this, one could hope to get arbitrarily close to
is some small positive quantity depending on . Iterating this, one could hope to get arbitrarily close to  .
.
A general principle with these sorts of continuous induction arguments is to first obtain the trivial implication  in a non-trivial fashion, with the hope that this non-trivial argument can somehow be perturbed or optimized to get the crucial improvement . The standard strategy for doing this, since the work of Bourgain and then Wolff in the 1990s (with precursors in older work of Córdoba), is to perform some sort of “induction on scales”. Here is the basic idea. Let us call the tubes in “thin tubes”. We can try to group these thin tubes into “fat tubes” of dimension
in a non-trivial fashion, with the hope that this non-trivial argument can somehow be perturbed or optimized to get the crucial improvement . The standard strategy for doing this, since the work of Bourgain and then Wolff in the 1990s (with precursors in older work of Córdoba), is to perform some sort of “induction on scales”. Here is the basic idea. Let us call the tubes in “thin tubes”. We can try to group these thin tubes into “fat tubes” of dimension  for some intermediate scale
for some intermediate scale  ; it is not terribly important for this sketch precisely what intermediate value is chosen here, but one could for instance set
; it is not terribly important for this sketch precisely what intermediate value is chosen here, but one could for instance set  if desired. Because of the -separated nature of the directions in , there can only be at most
if desired. Because of the -separated nature of the directions in , there can only be at most  thin tubes in a given fat tube, and so we need at least
thin tubes in a given fat tube, and so we need at least  fat tubes to cover the thin tubes. Let us suppose for now that we are in the “sticky” case where the thin tubes stick together inside fat tubes as much as possible, so that there are in fact a collection
fat tubes to cover the thin tubes. Let us suppose for now that we are in the “sticky” case where the thin tubes stick together inside fat tubes as much as possible, so that there are in fact a collection  of
of  fat tubes
fat tubes 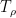 , with each fat tube containing about
, with each fat tube containing about  of the thin tubes. Let us also assume that the fat tubes are
of the thin tubes. Let us also assume that the fat tubes are  -separated in direction, which is an assumption which is highly consistent with the other assumptions made here.
-separated in direction, which is an assumption which is highly consistent with the other assumptions made here.
If we already have the hypothesis , then by applying it at scale instead of we conclude a lower bound on the volume occupied by fat tubes:

Since

, this morally tells us that the typical multiplicity

of the fat tubes is

; a typical point in

should belong to about

fat tubes.
Now, inside each fat tube , we are assuming that we have about thin tubes that are -separated in direction. If we perform a linear rescaling around the axis of the fat tube by a factor of 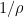 to turn it into a
to turn it into a  tube, this would inflate the thin tubes to be rescaled tubes of dimensions
tube, this would inflate the thin tubes to be rescaled tubes of dimensions  , which would now be
, which would now be  -separated in direction. This rescaling does not affect the multiplicity of the tubes. Applying again, we see morally that the multiplicity
-separated in direction. This rescaling does not affect the multiplicity of the tubes. Applying again, we see morally that the multiplicity  of the rescaled tubes, and hence the thin tubes inside , should be
of the rescaled tubes, and hence the thin tubes inside , should be  .
.
We now observe that the multiplicity  of the full collection of thin tubes should morally obey the inequality
of the full collection of thin tubes should morally obey the inequality

since if a given point lies in at most
fat tubes, and within each fat tube a given point lies in at most
thin tubes in that fat tube, then it should only be able to lie in at most

tubes overall. This heuristically gives

, which then recovers
(1) in the sticky case.
In their previous paper, Wang and Zahl were roughly able to squeeze a little bit more out of this argument to get something resembling  in the sticky case, loosely following a strategy of Nets Katz and myself that I discussed in this previous blog post from over a decade ago. I will not discuss this portion of the argument further here, referring the reader to the introduction to that paper; instead, I will focus on the arguments in the current paper, which handle the non-sticky case.
in the sticky case, loosely following a strategy of Nets Katz and myself that I discussed in this previous blog post from over a decade ago. I will not discuss this portion of the argument further here, referring the reader to the introduction to that paper; instead, I will focus on the arguments in the current paper, which handle the non-sticky case.
Let’s try to repeat the above analysis in a non-sticky situation. We assume (or some suitable variant thereof), and consider some thickened Kakeya set

where
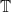
is something resembling what we might call a “Kakeya configuration” at scale
: a collection of

thin tubes of dimension
that are
-separated in direction. (Actually, to make the induction work, one has to consider a more general family of tubes than these, satisfying some standard “Wolff axioms” instead of the direction separation hypothesis; but we will gloss over this issue for now.) Our goal is to prove something like

for some
, which amounts to obtaining some improved volume bound

that improves upon the bound

coming from
. From the previous paper we know we can do this in the “sticky” case, so we will assume that

is “non-sticky” (whatever that means).
A typical non-sticky setup is when there are now  fat tubes for some multiplicity
fat tubes for some multiplicity  (e.g.,
(e.g.,  for some small constant
for some small constant 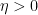 ), with each fat tube containing only
), with each fat tube containing only  thin tubes. Now we have an unfortunate imbalance: the fat tubes form a “super-Kakeya configuration”, with too many tubes at the coarse scale for them to be all -separated in direction, while the thin tubes inside a fat tube form a “sub-Kakeya configuration” in which there are not enough tubes to cover all relevant directions. So one cannot apply the hypothesis efficiently at either scale.
thin tubes. Now we have an unfortunate imbalance: the fat tubes form a “super-Kakeya configuration”, with too many tubes at the coarse scale for them to be all -separated in direction, while the thin tubes inside a fat tube form a “sub-Kakeya configuration” in which there are not enough tubes to cover all relevant directions. So one cannot apply the hypothesis efficiently at either scale.
This looks like a serious obstacle, so let’s change tack for a bit and think of a different way to try to close the argument. Let’s look at how intersects a given -ball  . The hypothesis suggests that might behave like a -dimensional fractal (thickened at scale ), in which case one might be led to a predicted size of
. The hypothesis suggests that might behave like a -dimensional fractal (thickened at scale ), in which case one might be led to a predicted size of  of the form
of the form  . Suppose for sake of argument that the set was denser than this at this scale, for instance we have
. Suppose for sake of argument that the set was denser than this at this scale, for instance we have

for all
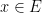
and some
. Observe that the
-neighborhood
is basically

, and thus has volume

by the hypothesis
(indeed we would even expect some gain in

, but we do not attempt to capture such a gain for now). Since
-balls have volume

, this should imply that
needs about

balls to cover it. Applying
(3), we then heuristically have

which would give the desired gain
. So we win if we can exhibit the condition
(3) for some intermediate scale
. I think of this as a “Frostman measure violation”, in that the
Frostman type bound 
is being violated.
The set , being the union of tubes of thickness , is essentially the union of  cubes. But it has been observed in several previous works (starting with a paper of Nets Katz, Izabella Laba, and myself) that these Kakeya type sets tend to organize themselves into larger “grains” than these cubes – in particular, they can organize into
cubes. But it has been observed in several previous works (starting with a paper of Nets Katz, Izabella Laba, and myself) that these Kakeya type sets tend to organize themselves into larger “grains” than these cubes – in particular, they can organize into  disjoint prisms (or “grains”) in various orientations for some intermediate scales
disjoint prisms (or “grains”) in various orientations for some intermediate scales  . The original “graininess” argument of Nets, Izabella and myself required a stickiness hypothesis which we are explicitly not assuming (and also an “x-ray estimate”, though Wang and Zahl were able to find a suitable substitute for this), so is not directly available for this argument; however, there is an alternate approach to graininess developed by Guth, based on the polynomial method, that can be adapted to this setting. (I am told that Guth has a way to obtain this graininess reduction for this paper without invoking the polynomial method, but I have not studied the details.) With rescaling, we can ensure that the thin tubes inside a single fat tube will organize into grains of a rescaled dimension
. The original “graininess” argument of Nets, Izabella and myself required a stickiness hypothesis which we are explicitly not assuming (and also an “x-ray estimate”, though Wang and Zahl were able to find a suitable substitute for this), so is not directly available for this argument; however, there is an alternate approach to graininess developed by Guth, based on the polynomial method, that can be adapted to this setting. (I am told that Guth has a way to obtain this graininess reduction for this paper without invoking the polynomial method, but I have not studied the details.) With rescaling, we can ensure that the thin tubes inside a single fat tube will organize into grains of a rescaled dimension  . The grains associated to a single fat tube will be essentially disjoint; but there can be overlap between grains from different fat tubes.
. The grains associated to a single fat tube will be essentially disjoint; but there can be overlap between grains from different fat tubes.
The exact dimensions  of the grains are not specified in advance; the argument of Guth will show that
of the grains are not specified in advance; the argument of Guth will show that  is significantly larger than , but other than that there are no bounds. But in principle we should be able to assume without loss of generality that the grains are as “large” as possible. This means that there are no longer grains of dimensions
is significantly larger than , but other than that there are no bounds. But in principle we should be able to assume without loss of generality that the grains are as “large” as possible. This means that there are no longer grains of dimensions  with
with  much larger than
much larger than  ; and for fixed , there are no wider grains of dimensions
; and for fixed , there are no wider grains of dimensions  with
with  much larger than .
much larger than .
One somewhat degenerate possibility is that there are enormous grains of dimensions approximately  (i.e.,
(i.e.,  ), so that the Kakeya set becomes more like a union of planar slabs. Here, it turns out that the classical arguments of Córdoba give good estimates, so this turns out to be a relatively easy case. So we can assume that least one of or is small (or both).
), so that the Kakeya set becomes more like a union of planar slabs. Here, it turns out that the classical arguments of Córdoba give good estimates, so this turns out to be a relatively easy case. So we can assume that least one of or is small (or both).
We now revisit the multiplicity inequality (2). There is something slightly wasteful about this inequality, because the fat tubes used to define occupy a lot of space that is not in . An improved inequality here is

where

is the multiplicity, not of the fat tubes
, but rather of the smaller set

. The point here is that by the graininess hypotheses, each
is the union of essentially disjoint grains of some intermediate dimensions
. So the quantity
is basically measuring the multiplicity of the grains.
It turns out that after a suitable rescaling, the arrangement of grains looks locally like an arrangement of tubes. If one is lucky, these tubes will look like a Kakeya (or sub-Kakeya) configuration, for instance with not too many tubes in a given direction. (More precisely, one should assume here some form of the Wolff axioms, which the authors refer to as the “Katz-Tao Convex Wolff axioms”). A suitable version if the hypothesis will then give the bound

Meanwhile, the thin tubes inside a fat tube are going to be a sub-Kakeya configuration, having about
times fewer tubes than a Kakeya configuration. It turns out to be possible to use
to then get a gain in
here,

for some small constant
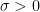
. Inserting these bounds into
(4), one obtains a good bound

which leads to the desired gain
.
So the remaining case is when the grains do not behave like a rescaled Kakeya or sub-Kakeya configuration. Wang and Zahl introduce a “structure theorem” to analyze this case, concluding that the grains will organize into some larger convex prisms  , with the grains in each prism behaving like a “super-Kakeya configuration” (with significantly more grains than one would have for a Kakeya configuration). However, the precise dimensions of these prisms is not specified in advance, and one has to split into further cases.
, with the grains in each prism behaving like a “super-Kakeya configuration” (with significantly more grains than one would have for a Kakeya configuration). However, the precise dimensions of these prisms is not specified in advance, and one has to split into further cases.
One case is when the prisms are “thick”, in that all dimensions are significantly greater than . Informally, this means that at small scales, looks like a super-Kakeya configuration after rescaling. With a somewhat lengthy induction on scales argument, Wang and Zahl are able to show that (a suitable version of) implies an “x-ray” version of itself, in which the lower bound of super-Kakeya configurations is noticeably better than the lower bound for Kakeya configurations. The upshot of this is that one is able to obtain a Frostman violation bound of the form (3) in this case, which as discussed previously is already enough to win in this case.
It remains to handle the case when the prisms are “thin”, in that they have thickness  . In this case, it turns out that the arguments of Córdoba, combined with the super-Kakeya nature of the grains inside each of these thin prisms, implies that each prism is almost completely occupied by the set . In effect, this means that these prisms themselves can be taken to be grains of the Kakeya set. But this turns out to contradict the maximality of the dimensions of the grains (if everything is set up properly). This treats the last remaining case needed to close the induction on scales, and obtain the Kakeya conjecture!
. In this case, it turns out that the arguments of Córdoba, combined with the super-Kakeya nature of the grains inside each of these thin prisms, implies that each prism is almost completely occupied by the set . In effect, this means that these prisms themselves can be taken to be grains of the Kakeya set. But this turns out to contradict the maximality of the dimensions of the grains (if everything is set up properly). This treats the last remaining case needed to close the induction on scales, and obtain the Kakeya conjecture!