Primitive sets and von Mangoldt chains: Erdős Problem #1196 and beyond
What's new 2026-05-04
Boris Alexeev, Kevin Barreto, Yanyang Li, Jared Duker Lichtman, Liam Price, Jibran Iqbal Shah, Quanyu Tang, and I have just uploaded to the arXiv our paper Primitive sets and von Mangoldt chains: Erdős Problem \#1196 and beyond. This paper (which is a work in progress) represents our efforts to digest and document the recent flurry of developments around the following problem of Erdős, Sárközy, and Szemerédi on primitive sets:
Conjecture 1 (Erdős problem #1196) Suppose thatis a primitive set, which means that no element of
divides another. Then
as
.

One can show that the upper bound of 



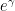
Theorem 2 (Erdős primitive set conjecture, #164) For any primitive,

Theorem 3 (Odd Banks–Martin) Letand suppose
where
denotes the primes appearing as factors of elements of
is the collection of products of

Theorem 4 (is Erdős-strong) If

Theorem 5 (Ahlswede–Khachatrian–Sárközy) Ifwhenever
.
![\displaystyle \sum_{n \in A \cap [y/x,y]} \frac{1}{n} \ll \frac{\log x}{\sqrt{\log\log x}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7Bn+%5Cin+A+%5Ccap+%5By%2Fx%2Cy%5D%7D+%5Cfrac%7B1%7D%7Bn%7D+%5Cll+%5Cfrac%7B%5Clog+x%7D%7B%5Csqrt%7B%5Clog%5Clog+x%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Theorem 6 (Erdős–Sárközy–Szemerédi, #1217) Letbe such that the upper doubly logarithmic density
is positive. Then there exists a strictly increasing infinite divisibility chain
in
![\displaystyle \Delta := \limsup_{x\rightarrow\infty}\frac{1}{\log\log x} f(A \cap [1,x])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CDelta+%3A%3D+%5Climsup_%7Bx%5Crightarrow%5Cinfty%7D%5Cfrac%7B1%7D%7B%5Clog%5Clog+x%7D+f%28A+%5Ccap+%5B1%2Cx%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)


Theorem 2 and Theorem 5 had been previously established by Lichtman and Ahlswede–Khachatrian–Sárközy respectively, but the Markov chain formalism gives shorter (and more unified) proofs of both. Theorems 3, 4, 6 were open conjectures that can now be settled by this method. These results were obtained with varying levels of AI involvement, ranging from completely autonomous AI queries to traditional pen-and-paper calculations, to various hybrid approaches (for instance, with humans suggesting key inequalities that could then be rapidly tested numerically or even proved by various AI tools).
— 1. Chain/antichain duality and Markov chains —
I’ll now discuss the basic method of proof and try to motivate the main ideas, which have become much clearer in retrospect. Primitive sets can be viewed as antichains in the divisibility poset 




One can attack this problem using the well known duality between antichains and chains 
 and any antichain . In particular, if one has a measure
and any antichain . In particular, if one has a measure  on the space
on the space  of all chains (viewed as a compact subspace of the power set of , equipped with the product topology) with the property that
of all chains (viewed as a compact subspace of the power set of , equipped with the product topology) with the property that 
 , then by integrating the previous inequality against and using Tonelli’s theorem one would obtain the upper bound
, then by integrating the previous inequality against and using Tonelli’s theorem one would obtain the upper bound 
In fact this duality is completely tight:
Proposition 7 (Chain/antichain duality) Let. Then the following are equivalent:
- (i)
for all antichains
- (ii) There exists a measure
on the space of chains, such that (1) holds for all
Proof: We have already indicated how (ii) implies (i). Now we need to show that (i) implies (ii). A standard compactness argument allows us to reduce to the case when

 in the Stanley chain polytope, defined as the convex hull of the indicator functions of antichains. By a classic result of Stanley, this polytope can also be defined as the space of all obeying the inequalities
in the Stanley chain polytope, defined as the convex hull of the indicator functions of antichains. By a classic result of Stanley, this polytope can also be defined as the space of all obeying the inequalities 

 ). Equivalently, we can find non-negative weights
). Equivalently, we can find non-negative weights  for each chain such that
for each chain such that 
 . The claim follows by viewing as a measure on the space of chains.
. The claim follows by viewing as a measure on the space of chains. 
Thus, the “universal” problem of obtaining a uniform upper bound on 

It turns out (in a manner that was not explicitly appreciated in past literature) that particularly good choices of random chain to use here can come from Markov chains. (Here, the term “chain” is now being used in two different ways, but fortunately the order-theoretic concept of a chain and the Markov process-theoretic concept of a chain will be quite compatible in this discussion.) There will be two types of Markov chains on the poset
Definition 8 (Downwards Markov chain) Letof
for
obeying the following axioms:
(Thus for instance one has
- (i)
, with equality unless
and
, or if
and
.
- (ii) For any
.
for any absorbing state
Given such a downwards Markov chain and an initial state 

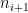



Theorem 9 (LYM inequality) Ifis the power set of
with the inclusion partial ordering, and

Proof: We introduce the downwards Markov chain with absorbing state 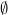

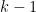






In the above argument we fixed the initial location 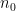


One can also define upwards Markov chains 


 , then we can define an adjoint upwards Markov chain (with no absorbing state) by the formula
, then we can define an adjoint upwards Markov chain (with no absorbing state) by the formula 
 in . More generally, if is merely sub-invariant in the sense that
in . More generally, if is merely sub-invariant in the sense that  , one can still construct an adjoint upwards chain as before, but now one must also add an additional absorbing maximal state
, one can still construct an adjoint upwards chain as before, but now one must also add an additional absorbing maximal state 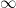 to ensure that the transition probabilities still sum to one.
to ensure that the transition probabilities still sum to one.A downwards or upwards Markov chain, when equipped with an invariant or sub-invariant measure, also induces a flow network on the poset, in which an edge from 

— 2. The Mertens and von Mangoldt chains —
For the purpose of analyzing primitive sets, there are two downward chains on the natural numbers (with absorbing state
- The downwards Mertens chain, in which each
transitions deterministically to
, where
is the largest prime factor of
- the downwards von Mangoldt chain, in which each
with probability
for each
dividing
the von Mangoldt function.
The von Mangoldt weight

The Mertens chain generates deterministic downward divisibility chains
 primes
primes  , and as such this process was implicit in much of the previous literature on primitive sets. However, it does not quite interact well with the
, and as such this process was implicit in much of the previous literature on primitive sets. However, it does not quite interact well with the  weight, which is not invariant or subinvariant with respect to this process. Intuitively, the process of dividing by tends to increasingly select for numbers for which is smaller than expected. Instead, the natural invariant measure for this chain is the Mertens weight
weight, which is not invariant or subinvariant with respect to this process. Intuitively, the process of dividing by tends to increasingly select for numbers for which is smaller than expected. Instead, the natural invariant measure for this chain is the Mertens weight  gives the upwards Mertens divisibility chain
gives the upwards Mertens divisibility chain  transitions to
transitions to 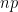 for some prime
for some prime  with probability
with probability  . A routine induction shows that each is hit by this chain with a probability of
. A routine induction shows that each is hit by this chain with a probability of  ; this for instance gives a weak version
; this for instance gives a weak version 
The key innovation (which was uncovered by the AI-assisted proofs, though not quite in the notation and framework presented here) is to switch to the von Mangoldt chain, which removes the bias towards numbers whose largest prime factor is small. Indeed, the weight 
 ) can eliminate the loss in the previous argument, and give one of the proofs of Theorem 1 recorded in our paper (there are several other variants of this method that we also present).
) can eliminate the loss in the previous argument, and give one of the proofs of Theorem 1 recorded in our paper (there are several other variants of this method that we also present).One slight defect of the von Mangoldt chain, as compared to the Mertens chain, is that it can “jump over” primitive sets (such as the set of products of
In order to establish some crucial sub-invariance properties, it turns out (after some standard manipulations) to be useful to obtain good bounds on the negative log-derivative

 in the region
in the region 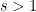 . Here it turns out that there is a clean (and rather efficient) upper bound
. Here it turns out that there is a clean (and rather efficient) upper bound 

 probabilistically as
probabilistically as 
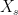 is a gamma random variable of shape
is a gamma random variable of shape  and scale . Because the sum of independent copies of and
and scale . Because the sum of independent copies of and  has the distribution of
has the distribution of  , one can couple together all the so that they are increasing in , at which point the claim follows.
, one can couple together all the so that they are increasing in , at which point the claim follows.— 3. Further directions —
Will Sawin and Ofir Gorodetsky have obtained analogues of several of the above results for function field models or permutation models respectively; we briefly discuss these in the paper, although we do not plan to cover these models in depth. We also note another recent use of this technique to solve a separate Erdős problem (\#858) relating to antichains in a variant of the divisibility poset.
The zeta process that we have discovered hints at an emerging theory of the “developmental anatomy of integers”, which differs from the existing topic of anatomy of integers in that it views a large integer
The paper is currently a work in progress; we have released an early version due to the public interest in this problem. We plan to explore some further applications, and also to formalize more of the above results in Lean (currently two of the six main theorems are formalized), before submitting the paper for publication. The situation here highlights a distinction I have recently made between three components of the problem solving process in mathematics, namely proof generation, proof verification, and proof digestion. In this particular case, the first two steps were extremely rapid due to modern AI tools; however, properly digesting the AI-generated proofs into a coherent exposition that places the arguments in context with both past literature and future directions remains a slower process that requires expert human attention.