PDF Object Streams, (Mon, Nov 11th)
SANS Internet Storm Center, InfoCON: green 2024-11-11
The first thing to do, when analyzing a potentially malicious PDF, is to look for the /Encrypt name as explained in diary entry Analyzing an Encrypted Phishing PDF.
The second thing to do, is to look for the /ObjStm name, as I will explain in this diary entry.
Take this phishing PDF and analyze it with pdfid.py, like this:
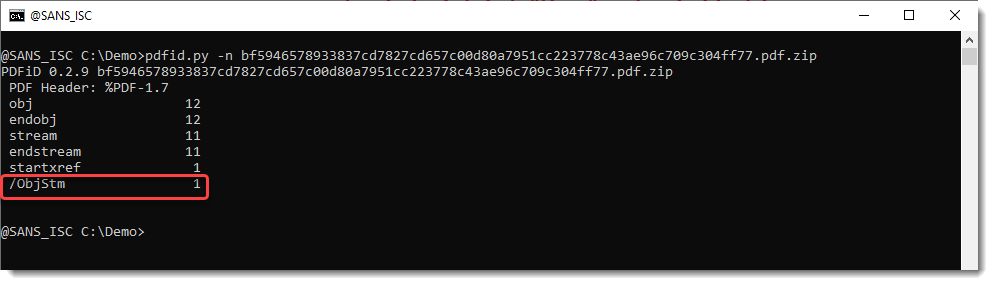
The presence of name /ObjStm tells us that there are Object Streams inside the PDF: an Object Stream is an object with a stream, that contains other objects (without stream). Since streams are usually compressed, pdfid.py is not able to find the keywords of the objects inside the Object Stream (since pdfid is a kind of string search tool that doesn't parse the structure of PDF documents). You need to use pdf-parser.py in stead.
Use option -a to let pdf-parser.py produce statistics and option -O to parse Object Streams. Like this:
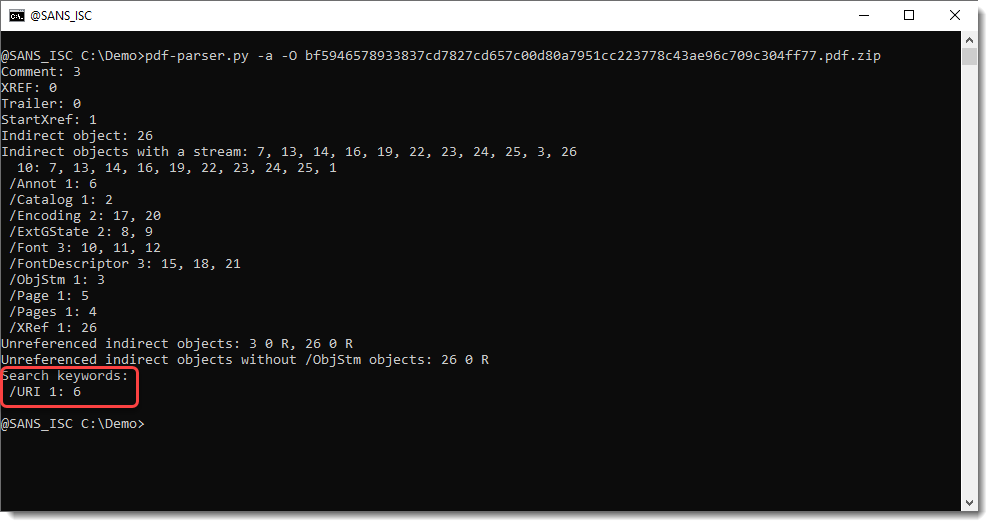
At the end of the statistics report, you will see the search keywords report, reporting names similar to pdfid.py's names report.
But here, you also get the index of the objects with these names, not just a counter like pdfid.py does. So there is 1 /URI name, and it is in object 6.
Next we take a look at object 6 with pdf-parser.py:
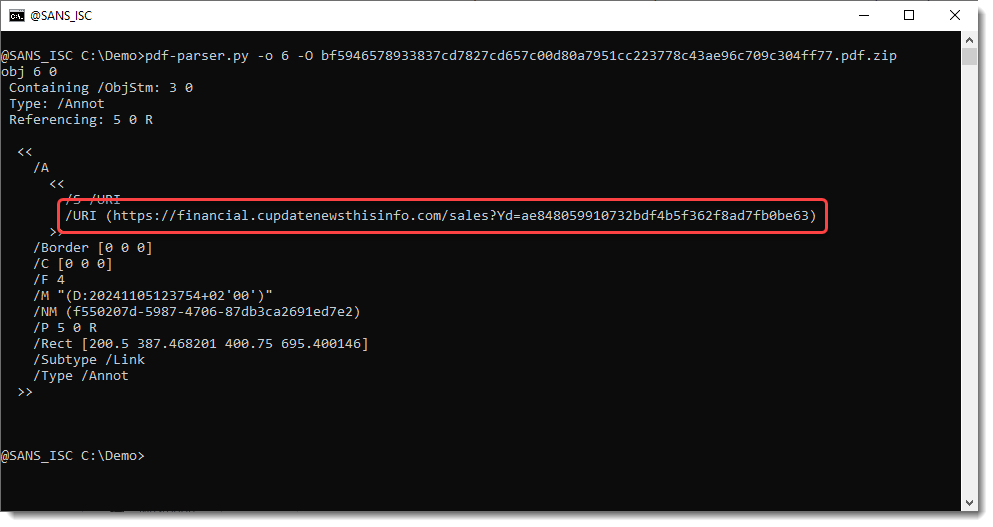
And that reveals the phishing URL.
Another method to find URIs is to use the keyword option (-k), like this:

To summarize: first look for /Encrypt, then /ObjStm, and then start your analysis.
Didier Stevens Senior handler blog.DidierStevens.com
(c) SANS Internet Storm Center. https://isc.sans.edu Creative Commons Attribution-Noncommercial 3.0 United States License.